

{kind=link}
Xiaomi’s MiMo workforce launched MiMo-Audio, a 7-billion-parameter audio-language mannequin that runs a single next-token goal over interleaved textual content and discretized speech, scaling pretraining past 100 million hours of audio.
What’s truly new?
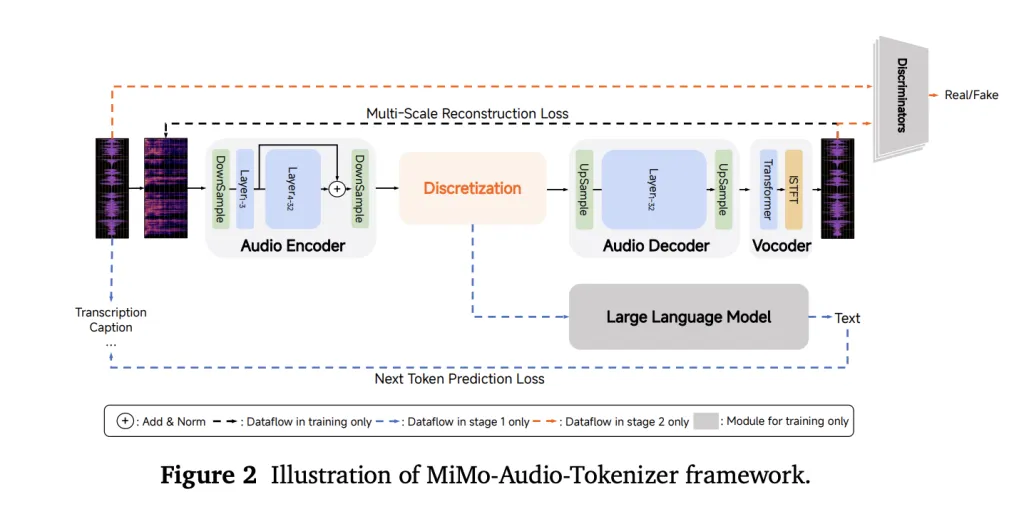
As an alternative of counting on task-specific heads or lossy acoustic tokens, MiMo-Audio makes use of a bespoke RVQ (residual vector quantization) tokenizer that targets each semantic constancy and high-quality reconstruction. The tokenizer runs at 25 Hz and outputs 8 RVQ layers (≈200 tokens/s), giving the LM entry to “lossless” speech options it may well mannequin autoregressively alongside textual content.
Structure: patch encoder → 7B LLM → patch decoder
To deal with the audio/textual content charge mismatch, the system packs 4 timesteps per patch for LM consumption (downsampling 25 Hz → 6.25 Hz), then reconstructs full-rate RVQ streams with a causal patch decoder. A delayed multi-layer RVQ technology scheme staggers predictions per codebook to stabilize synthesis and respect inter-layer dependencies. All three elements—patch encoder, MiMo-7B spine, and patch decoder—are skilled underneath a single next-token goal.
Scale is the algorithm
Coaching proceeds in two large phases: (1) an “understanding” stage that optimizes text-token loss over interleaved speech-text corpora, and (2) a joint “understanding + technology” stage that activates audio losses for speech continuation, S2T/T2S duties, and instruction-style knowledge. The report emphasizes a compute/knowledge threshold the place few-shot habits seems to “swap on,” echoing emergence curves seen in massive text-only LMs.
Benchmarks: speech intelligence and common audio
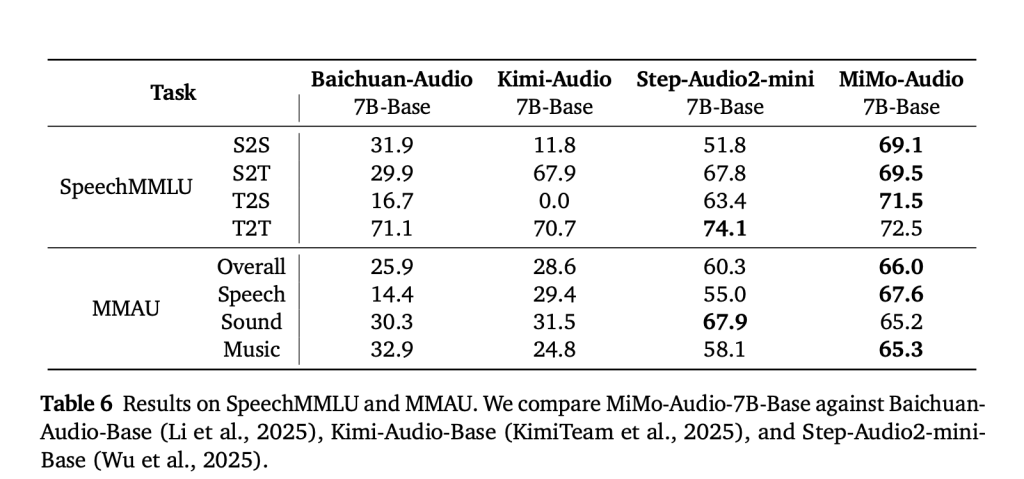
MiMo-Audio is evaluated on speech-reasoning suites (e.g., SpeechMMLU) and broad audio understanding benchmarks (e.g., MMAU), reporting sturdy scores throughout speech, sound, and music and a decreased “modality hole” between text-only and speech-in/speech-out settings. Xiaomi additionally releases MiMo-Audio-Eval, a public toolkit to breed these outcomes. Pay attention-and-respond demos (speech continuation, voice/emotion conversion, denoising, and speech translation) can be found on-line.
Why that is essential?
The method is deliberately easy—no multi-head activity tower, no bespoke ASR/TTS goals at pretraining time—simply GPT-style next-token prediction over lossless audio tokens plus textual content. The important thing engineering concepts are (i) a tokenizer the LM can truly use with out throwing away prosody and speaker id; (ii) patchification to maintain sequence lengths manageable; and (iii) delayed RVQ decoding to protect high quality at technology time. For groups constructing spoken brokers, these design selections translate into few-shot speech-to-speech enhancing and strong speech continuation with minimal task-specific finetuning.
6 Technical Takeaways:
- Excessive-Constancy Tokenization
MiMo-Audio makes use of a customized RVQ tokenizer working at 25 Hz with 8 energetic codebooks, guaranteeing speech tokens protect prosody, timbre, and speaker id whereas preserving them LM-friendly. - Patchified Sequence Modeling
The mannequin reduces sequence size by grouping 4 timesteps into one patch (25 Hz → 6.25 Hz), letting the 7B LLM deal with lengthy speech effectively with out discarding element. - Unified Subsequent-Token Goal
Relatively than separate heads for ASR, TTS, or dialogue, MiMo-Audio trains underneath a single next-token prediction loss throughout interleaved textual content and audio, simplifying structure whereas supporting multi-task generalization. - Emergent Few-Shot Talents
Few-shot behaviors comparable to speech continuation, voice conversion, emotion switch, and speech translation emerge as soon as coaching surpasses a large-scale knowledge threshold (~100M hours, trillions of tokens). - Benchmark Management
MiMo-Audio units state-of-the-art scores on SpeechMMLU (S2S 69.1, T2S 71.5) and MMAU (66.0 general), whereas minimizing the text-to-speech modality hole to only 3.4 factors. - Open Ecosystem Launch
Xiaomi supplies the tokenizer, 7B checkpoints (base and instruct), MiMo-Audio-Eval toolkit, and public demos, enabling researchers and builders to check and lengthen speech-to-speech intelligence in open-source pipelines.
Abstract
MiMo-Audio demonstrates that high-fidelity, RVQ-based “lossless” tokenization mixed with patchified next-token pretraining at scale is adequate to unlock few-shot speech intelligence with out task-specific heads. The 7B stack—tokenizer → patch encoder → LLM → patch decoder—bridges the audio/textual content charge hole (25→6.25 Hz) and preserves prosody and speaker id by way of delayed multi-layer RVQ decoding. Empirically, the mannequin narrows the textual content↔speech modality hole, generalizes throughout speech/sound/music benchmarks, and helps in-context S2S enhancing and continuation.
Take a look at the Paper, Technical particulars and GitHub Web page. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.