

{kind=link}

# Introduction
Pandas is among the hottest Python libraries for information evaluation. It provides you easy instruments for cleansing, reshaping, summarizing, and exploring structured information. Some of the helpful options in pandas is GroupBy. It helps you reply questions that require grouping rows by a number of classes.
For instance, in case you are working with gross sales information, you could need to calculate complete income by area, common order worth by product class, or the variety of orders dealt with by every gross sales consultant. As a substitute of manually filtering every class one after the other, GroupBy helps you to carry out these calculations in a clear and environment friendly method.
On this tutorial, we are going to stroll by sensible examples of utilizing Pandas GroupBy with a small gross sales dataset. I’m utilizing Deepnote because the coding atmosphere, so some outputs are proven as pocket book screenshots instantly below the code blocks.
# Making a Pattern Dataset
Earlier than utilizing GroupBy, we first create a small retail gross sales dataset with columns resembling order_id, area, class, sales_rep, items, unit_price, low cost, and order_date. We then convert the dictionary right into a pandas DataFrame and create two new columns: gross_sales and net_sales.
information = {
"order_id": [101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112],
"area": ["North", "South", "North", "West", "South", "West", "North", "South", "West", "North", "South", "West"],
"class": ["Electronics", "Furniture", "Electronics", "Furniture", "Clothing", "Electronics",
"Clothing", "Furniture", "Clothing", "Furniture", "Electronics", "Clothing"],
"sales_rep": ["Ayesha", "Bilal", "Ayesha", "Chen", "Bilal", "Chen",
"Ayesha", "Bilal", "Chen", "Ayesha", "Bilal", "Chen"],
"items": [2, 1, 3, 2, 5, 4, 6, 2, 7, 1, 2, 8],
"unit_price": [500, 800, 450, 700, 60, 550, 55, 850, 65, 750, 520, 70],
"low cost": [0.05, 0.10, 0.00, 0.08, 0.00, 0.12, 0.05, 0.10, 0.00, 0.07, 0.03, 0.00],
"order_date": pd.to_datetime([
"2026-01-05", "2026-01-06", "2026-01-08", "2026-01-10",
"2026-01-12", "2026-01-15", "2026-02-02", "2026-02-05",
"2026-02-08", "2026-02-12", "2026-02-15", "2026-02-20"
])
}
df = pd.DataFrame(information)
df["gross_sales"] = df["units"] * df["unit_price"]
df["net_sales"] = df["gross_sales"] * (1 - df["discount"])
df
The gross_sales column is calculated by multiplying items by unit_price, whereas net_sales adjusts that worth after making use of the low cost. This provides us a clear dataset that we will use for all GroupBy examples.
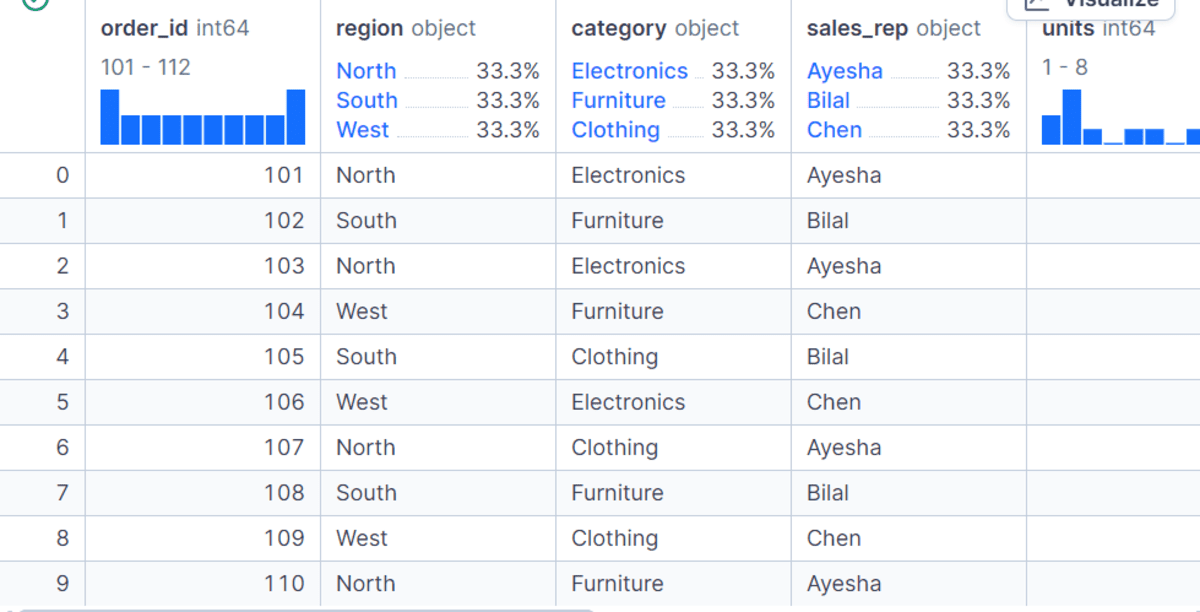
# Utilizing the Fundamental GroupBy Syntax
Probably the most primary GroupBy operation follows a easy sample: choose a grouping column, choose the worth column, and apply an aggregation perform. On this instance, we group the info by area and calculate the entire net_sales for every area.
df.groupby("area")["net_sales"].sum()
The end result exhibits that North, South, and West every have their very own complete gross sales worth. That is the only and most typical use case for GroupBy when summarizing information.
area
North 3311.0
South 3558.8
West 4239.0
Identify: net_sales, dtype: float64
# Utilizing GroupBy With as_index=False
By default, pandas makes use of the grouped column because the index within the output. Whereas that is helpful in some instances, it’s typically simpler to work with a traditional DataFrame the place the grouped column stays a daily column. That’s the place as_index=False is helpful.
df.groupby("area", as_index=False)["net_sales"].sum()
On this instance, we once more calculate complete internet gross sales by area, however the result’s returned as a clear DataFrame, which is less complicated to export, merge, or use in studies.

# Making use of A number of Aggregations on One Column
GroupBy will not be restricted to a single calculation. You may apply a number of aggregation capabilities to the identical column utilizing agg().
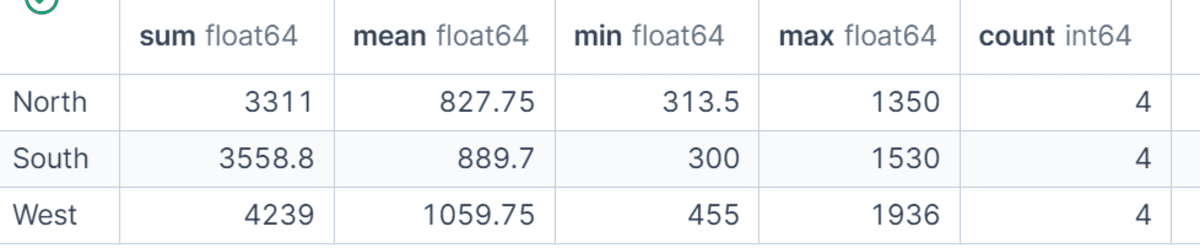
On this instance, we calculate the sum, imply, minimal, most, and rely of net_sales for every area.
This provides us a fast statistical abstract of regional gross sales efficiency and helps us evaluate not solely complete income but additionally common order measurement and order quantity.
df.groupby("area")["net_sales"].agg(["sum", "mean", "min", "max", "count"])
# Utilizing Named Aggregations
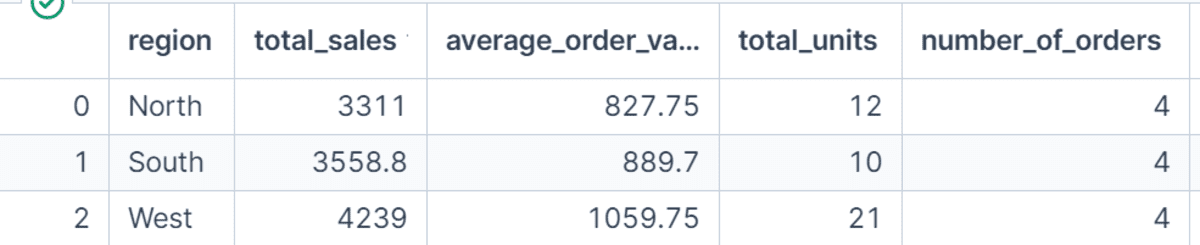
Named aggregations make GroupBy outputs simpler to learn and use. As a substitute of returning generic column names like sum or imply, we outline our personal names resembling total_sales, average_order_value, total_units, and number_of_orders.
That is particularly useful when getting ready evaluation for dashboards, studies, or tutorials as a result of the output column names clearly clarify what every metric represents.
region_summary = (
df.groupby("area", as_index=False)
.agg(
total_sales=("net_sales", "sum"),
average_order_value=("net_sales", "imply"),
total_units=("items", "sum"),
number_of_orders=("order_id", "rely")
)
)
region_summary
# Grouping by A number of Columns
You can even group information by a couple of column. On this instance, we group by each area and class to calculate complete internet gross sales for every product class inside every area.
This provides us a extra detailed view of the info in comparison with grouping by area alone. Multi-column grouping is helpful whenever you need to analyze efficiency throughout totally different dimensions, resembling area and product, division and worker, or month and buyer section.
df.groupby(["region", "category"], as_index=False)["net_sales"].sum() 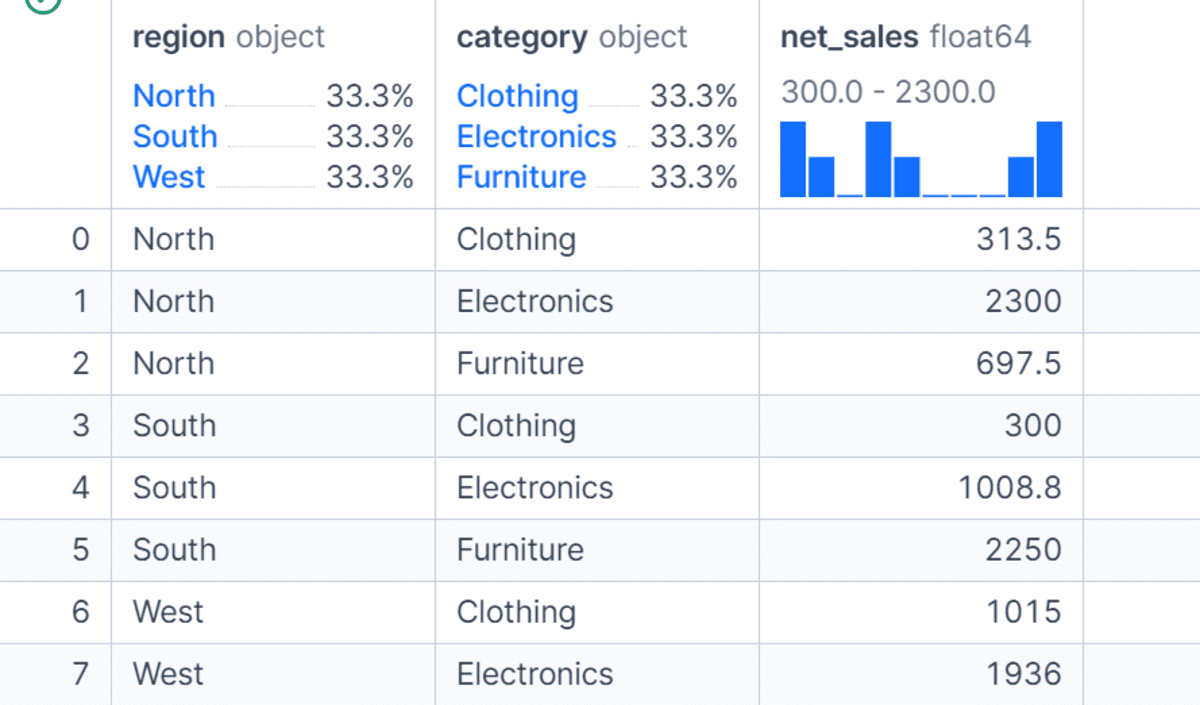
# Sorting GroupBy Outcomes
After grouping and aggregating information, you typically need to kind the outcomes to seek out the best or lowest values.
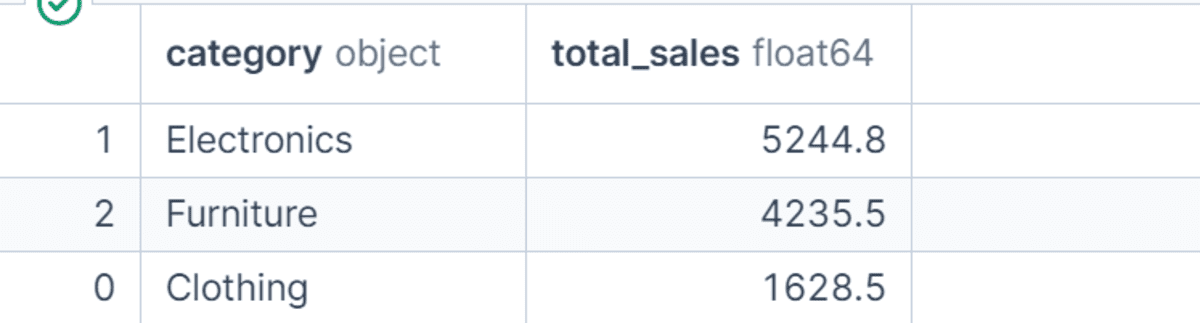
On this instance, we calculate complete gross sales by product class after which kind the leads to descending order.
This makes it straightforward to determine which class generated essentially the most income. Sorting grouped outcomes is a straightforward however highly effective step when turning uncooked summaries into helpful insights.
category_sales = (
df.groupby("class", as_index=False)
.agg(total_sales=("net_sales", "sum"))
.sort_values("total_sales", ascending=False)
)
category_sales
# Understanding Depend vs Measurement
Pandas offers each rely() and measurement(), however they aren’t precisely the identical. The measurement() technique counts the entire variety of rows in every group, together with rows with lacking values. The rely() technique counts solely non-missing values in a specific column.
On this instance, we deliberately add a lacking worth to the sales_rep column. The output exhibits that measurement() nonetheless counts 4 rows for every area, whereas rely() returns three for North as a result of one sales_rep worth is lacking.
import numpy as np
df_missing = df.copy()
df_missing.loc[2, "sales_rep"] = np.nan
print("Utilizing measurement():")
show(df_missing.groupby("area").measurement())
print("Utilizing rely() on sales_rep:")
show(df_missing.groupby("area")["sales_rep"].rely())
Output:
Utilizing measurement():
area
North 4
South 4
West 4
dtype: int64
Utilizing rely() on sales_rep:
area
North 3
South 4
West 4
Identify: sales_rep, dtype: int64
# Utilizing remodel() for Group-Stage Options
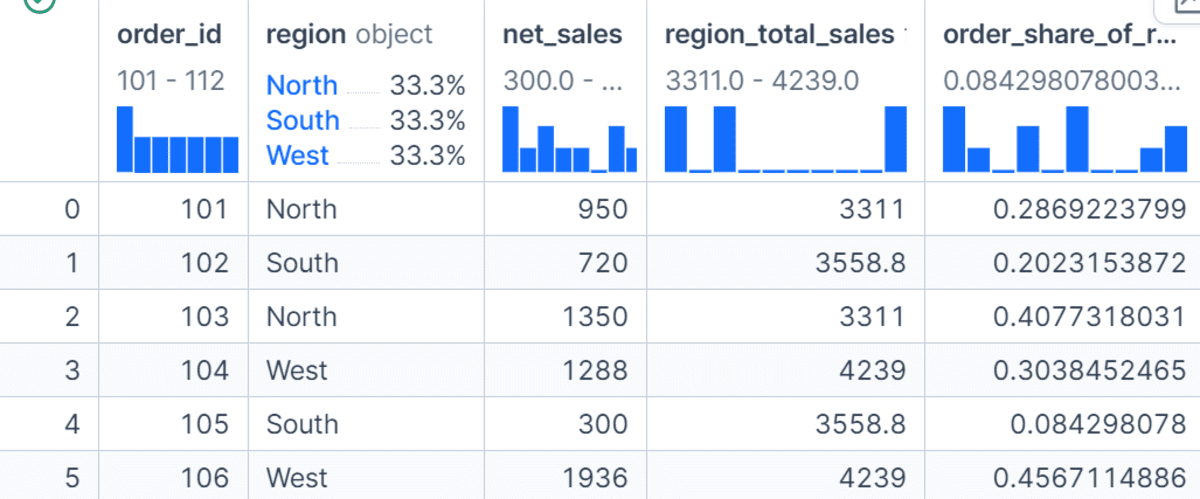
The remodel() technique is helpful whenever you need to calculate a group-level worth and add it again to the unique DataFrame.
On this instance, we calculate complete gross sales for every area and retailer it in a brand new column known as region_total_sales.
We then calculate every order’s share of its area’s complete gross sales. In contrast to agg(), which reduces the info to at least one row per group, remodel() returns values aligned with the unique rows, making it very helpful for function engineering.
df["region_total_sales"] = df.groupby("area")["net_sales"].remodel("sum")
df["order_share_of_region"] = df["net_sales"] / df["region_total_sales"]
df[["order_id", "region", "net_sales", "region_total_sales", "order_share_of_region"]]
# Filtering Teams With filter()
The filter() technique helps you to preserve or take away whole teams primarily based on a situation. On this instance, we preserve solely the areas the place complete internet gross sales are larger than 3,000.
As a substitute of returning one abstract row per group, filter() returns the unique rows from the teams that meet the situation. That is helpful whenever you need to take away low-performing teams or preserve solely teams that fulfill a enterprise rule.
high_sales_regions = df.groupby("area").filter(lambda group: group["net_sales"].sum() > 3000)
high_sales_regions 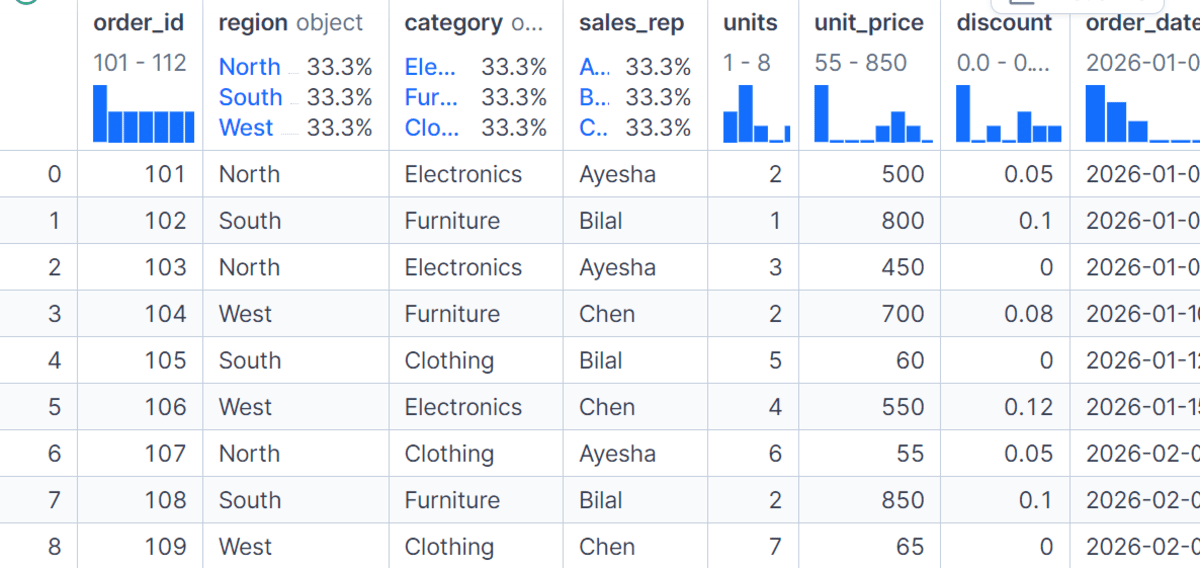
# Making use of Customized Logic With apply()
The apply() technique provides you extra flexibility as a result of it permits you to run customized logic on every group.
On this instance, we use apply() with nlargest() to seek out the highest order by internet gross sales in every area. That is helpful when built-in aggregation capabilities are usually not sufficient on your evaluation.
Nevertheless, apply() could be slower than built-in strategies like sum(), imply(), agg(), and remodel(), so it’s best to make use of it solely whenever you want customized group-wise operations.
top_order_by_region = (
df.groupby("area", group_keys=False)
.apply(lambda group: group.nlargest(1, "net_sales"))
)
top_order_by_region

# Grouping by Dates
GroupBy can be very helpful for time-based evaluation.
On this instance, we extract the month from the order_date column and group the info by month.
We then calculate complete gross sales and complete orders for every month. This method is useful when analyzing traits over time, resembling month-to-month gross sales, weekly person exercise, or yearly income development.
df["month"] = df["order_date"].dt.to_period("M").astype(str)
monthly_sales = (
df.groupby("month", as_index=False)
.agg(total_sales=("net_sales", "sum"), total_orders=("order_id", "rely"))
)
monthly_sales

# Grouping by Dates With pd.Grouper
pd.Grouper offers a cleaner method to group time collection information with out manually making a separate month column.
On this instance, we group the DataFrame by order_date utilizing a month-to-month frequency and calculate complete gross sales and complete orders.
That is particularly helpful when working with real-world datasets that include timestamps and also you need to summarize information by day, week, month, quarter, or 12 months.
monthly_sales_grouper = (
df.groupby(pd.Grouper(key="order_date", freq="M"))
.agg(total_sales=("net_sales", "sum"), total_orders=("order_id", "rely"))
.reset_index()
)
monthly_sales_grouper 
# Making a Pivot-Type Abstract With GroupBy
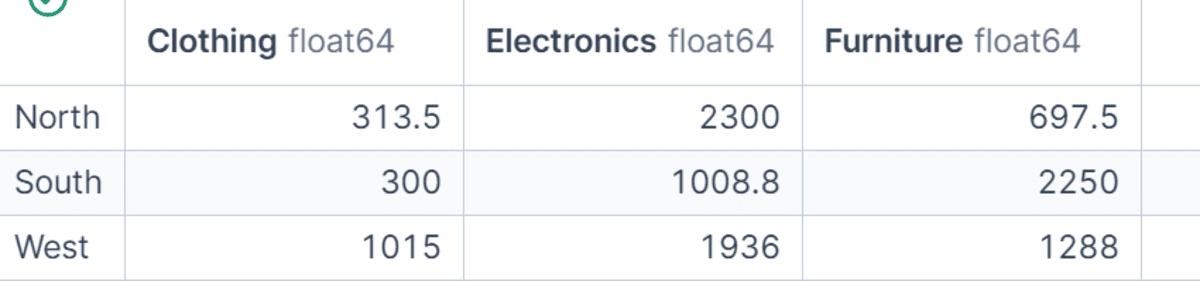
You may mix groupby() with unstack() to create a pivot-style abstract desk.
On this instance, we group the info by area and class, calculate complete internet gross sales, after which reshape the end result in order that classes change into columns. This makes the output simpler to match throughout areas and classes. It’s a nice approach whenever you need a compact desk for reporting or fast evaluation.
region_category_table = (
df.groupby(["region", "category"])["net_sales"]
.sum()
.unstack(fill_value=0)
)
region_category_table
# Conclusion
Pandas GroupBy is among the strongest instruments for information evaluation in Python. It helps you summarize information, evaluate teams, create new options, filter outcomes, and apply customized calculations with out writing pointless handbook logic.
Whereas engaged on this tutorial, I noticed how a lot depth there may be in GroupBy. Even after working with information for years, I realized new and higher methods to unravel widespread issues. Options like pd.Grouper, customized aggregation capabilities, and remodel() stood out as a result of they make many duties quicker, cleaner, and simpler to take care of.
That is additionally why understanding the native instruments issues. It’s tempting to depend on vibe coding or fast customized options, however these can typically produce slower, extra sophisticated code. When you recognize what pandas already offers, you may write options which are extra environment friendly, reusable, and sensible for real-world information evaluation.
On this tutorial, we lined essentially the most helpful GroupBy operations, together with primary aggregation, named aggregation, multi-column grouping, sorting, rely() vs measurement(), remodel(), filter(), apply(), date grouping, and pivot-style summaries. When you perceive these patterns, you should use GroupBy to reply many real-world information evaluation questions shortly and confidently.
Abid Ali Awan (@1abidaliawan) is an authorized information scientist skilled who loves constructing machine studying fashions. At the moment, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in expertise administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students scuffling with psychological sickness.