

{kind=link}
In case you’ve ever watched a movement seize system battle with an individual’s fingers, or seen a segmentation mannequin fail to differentiate tooth from gums, you already perceive why human-centric laptop imaginative and prescient is difficult. People will not be simply objects, they arrive with articulated construction, nice floor particulars, and large variation in pose, clothes, lighting, and ethnicity. Getting a mannequin to grasp all of that, directly, throughout arbitrary real-world pictures, is genuinely tough.
Meta AI analysis crew launched Sapiens2, the second era of its basis mannequin household for human-centric imaginative and prescient. Skilled on a newly curated dataset of 1 billion human pictures, spanning mannequin sizes from 0.4B to 5B parameters, and designed to function at native 1K decision with hierarchical variants supporting 4K, Sapiens2 is a considerable leap over its predecessor throughout each benchmark the crew evaluated.
What Sapiens2 is Making an attempt to Remedy
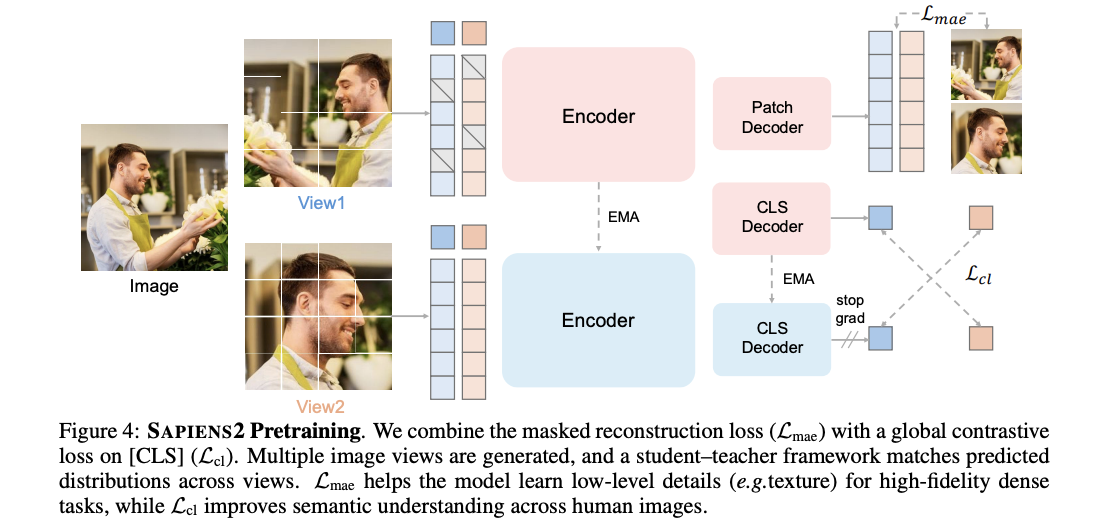
The unique Sapiens mannequin relied totally on Masked Autoencoder (MAE) pretraining. MAE works by masking a big portion of enter picture patches, 75% on this case, and coaching the mannequin to reconstruct the lacking pixels. This forces the mannequin to be taught spatial particulars and textures, which is helpful for dense prediction duties like segmentation or depth estimation.

The issue is that MAE, as a type of masked picture modeling (MIM), learns largely by way of compression. It doesn’t naturally be taught high-level semantics. It may inform you what one thing appears to be like like, however not essentially what it means within the context of a human physique. That’s the place contrastive studying (CL) strategies like DINO and SimCLR shine: they manage representations semantically by coaching the mannequin to deal with totally different views of the identical picture as comparable and views of various pictures as distinct.
However CL has its personal tradeoff. Its aggressive augmentation methods like shade jitter, blurring, can strip away look cues like pores and skin tone or lighting situations which can be essential for duties like albedo estimation (recovering the true shade of a floor unbiased of lighting). That is what the analysis crew calls illustration drift.
Sapiens2 addresses this drawback immediately by combining each aims: a masked picture reconstruction loss (LMAE) to protect low-level constancy, and a world contrastive loss (LCL) on the [CLS] token utilizing a student-teacher framework primarily based on DINOv3, the place the trainer’s parameters are an exponential shifting common (EMA) of the coed. Crucially, shade augmentations are not utilized to world views used for the MAE goal, preserving the looks cues wanted for photorealistic duties. The joint goal is L = LMAE + λLCL.
The Knowledge: People-1B
Getting 1 billion coaching pictures proper required a multi-stage filtering pipeline. Ranging from a web-scale pool of roughly 4 billion pictures, Meta crew utilized bounding field detection, head-pose estimation, aesthetic and realism scoring, CLIP-based function filtering, and text-overlay detection. The result’s a curated corpus the place each picture accommodates at the least one outstanding particular person with a minimal short-side decision of 384 pixels.
To make sure variety, the analysis crew used perceptual hashing and deep-feature nearest-neighbor pruning for deduplication, then clustered visible embeddings and utilized selective sampling to stability the dataset throughout poses, viewpoints, occlusion ranges, clothes sorts, and lighting situations. No job labels or human-specific priors had been injected throughout pretraining — simply pictures.
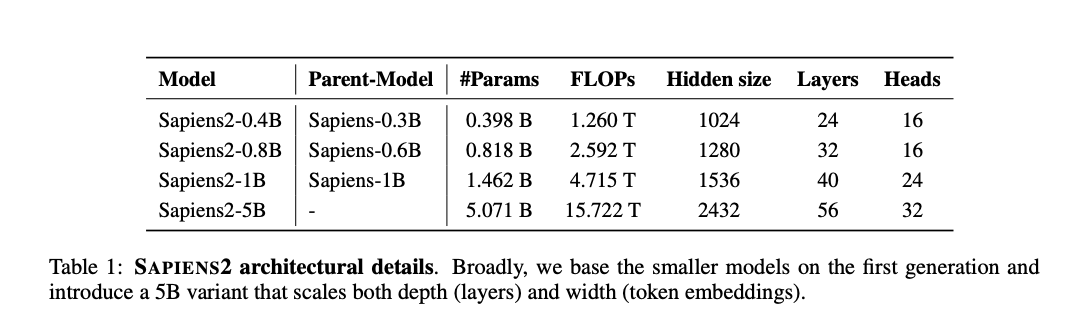
The Structure: Scaling to 5B and 4K
Sapiens2 introduces 4 mannequin sizes: 0.4B, 0.8B, 1B, and 5B parameters, every at native 1K decision. The 5B mannequin is the highest-FLOPs imaginative and prescient transformer reported to this point at 15.722 TFLOPs.
For 4K decision, the analysis crew adopted a hierarchical windowed consideration design. The primary Okay layers apply windowed self-attention regionally to seize nice texture and limits inside spatial home windows. A [CLS]-guided pooling step then downsamples the 2D token grid by a spatial stride √ω, and the following L layers apply world self-attention over this diminished sequence. This format is appropriate with MAE-style pretraining as a result of masked tokens will be dropped after the native stage, stopping info from leaking throughout masked areas — an issue that convolutional backbones sometimes want masked convolutions to keep away from.
The masking technique itself can be rigorously designed: Sapiens2 makes use of blended blockwise/patchwise masking (blockwise likelihood 0.4) at a 75% masks ratio with patch measurement 16. At 1024×768 decision (64×48 = 3072 patches), this masks roughly 2304 patches per picture which is sufficient to create coarse occlusions that regularize MAE whereas preserving enough context for the contrastive goal.
For stability at scale, the structure incorporates a number of enhancements: RMSNorm changing LayerNorm, Grouped-Question Consideration (GQA) in mid-depth blocks for increased throughput, QK-Norm for strong high-resolution coaching, and SwiGLU feed-forward layers. The decoder makes use of pixel-shuffle upsampling for sub-pixel reasoning. Decoder output decision was additionally elevated from 0.5K to 1K for base backbones, and to 2K for 4K backbones.
Publish-Coaching: 5 Human Duties, 10× Extra Supervision
A essential enchancment over the unique Sapiens is the dimensions and high quality of task-specific supervision. Relative to the primary era, Sapiens2 scales task-specific labels by 10×, sometimes reaching round 1 million labels per job. After pretraining, the spine is fine-tuned for 5 downstream duties utilizing light-weight task-specific heads whereas leaving the spine unchanged:
- Pose Estimation: A 308-keypoint full-body skeleton with dense face (243 keypoints) and hand (40 keypoints) protection. The analysis crew newly annotated 100K in-the-wild pictures to enhance studio seize information, enhancing generalization considerably.
- Physique-Half Segmentation: 29 semantic lessons (prolonged from 28 by including eyeglasses), educated with per-pixel weighted cross-entropy mixed with Cube loss for sharper boundaries.
- Pointmap Estimation: Fairly than predicting relative depth, Sapiens2 regresses a per-pixel 3D pointmap P̂(u) ∈ ℝ³ within the digital camera body — a more durable job that requires reasoning about digital camera intrinsics.
- Regular Estimation: Per-pixel floor unit normals, decoded utilizing a number of PixelShuffle layers for artifact-free upsampling.
- Albedo Estimation: Per-pixel diffuse albedo Â(u) ∈ [0,1]³, educated purely on artificial high-fidelity information and designed to get well true pores and skin tone and clothes shade beneath various illumination.
Outcomes
The numbers are tough to argue with. On the 11K-image in-the-wild pose take a look at set, Sapiens2-5B achieves 82.3 mAP in comparison with 78.3 mAP for Sapiens-2B — a +4 mAP enchancment. On body-part segmentation, even the smallest mannequin, Sapiens2-0.4B, scores 79.5 mIoU (+21.3 over Sapiens-2B*), whereas Sapiens2-5B reaches 82.5 mIoU — a +24.3 mIoU achieve over the earlier era’s largest mannequin. The 4K variant, Sapiens2-1B-4K, additional pushes segmentation to 81.9 mIoU and 92.0 mAcc, demonstrating the advantage of higher-resolution reasoning.
On floor regular estimation, Sapiens2-0.4B already achieves a imply angular error of 8.63°, outperforming the earlier state-of-the-art DAViD-L at 10.73°. The 5B mannequin brings this down additional to 6.73°, and the 4K variant reaches 6.98° with a median angular error of simply 3.08°.
For albedo estimation, Sapiens2-5B achieves an MAE of 0.012 and a PSNR of 32.61 dB, with constant enchancment throughout all mannequin sizes. On pointmap estimation, all Sapiens2 mannequin sizes outperform MoGe, which was beforehand state-of-the-art for monocular geometry estimation.
In dense probing evaluations, the place the spine is frozen and solely light-weight decoders are educated with an identical hyperparameters, Sapiens2-5B surpasses all baselines throughout each job, together with DINOv3-7B (6.71B parameters), regardless of Sapiens2 being a human-specialist mannequin evaluated towards a general-purpose spine almost 1.5× its measurement.
Try the Mannequin Weights with Demos, Paper and Repo. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 130k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be a part of us on telegram as properly.
Must accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us