
")
{kind=link}
")
# Introduction
I do know that when rookies begin studying machine studying, issues appear straightforward at first. You observe a tutorial that asks you to load a dataset, practice a mannequin, and you then see one thing like this: loss = "mse" or criterion = nn.CrossEntropyLoss().
And identical to that, the tutorial begins speaking about equations, gradients, optimization, and Greek letters. In case you have ever nodded alongside with out actually understanding what a loss perform does, you aren’t alone. Loss capabilities are sometimes defined backward. Most tutorials begin with the formulation when they need to begin with the thought. This text is a part of my noob collection, the place I’ll make issues simpler so that you can perceive. So, let’s get began.
# What Is a Loss Operate?
A loss perform is how a machine studying mannequin is aware of how improper it’s. That’s actually the entire idea. The mannequin makes a prediction. The loss perform compares that prediction with the right reply. Then it provides the mannequin a quantity that claims, “That is how dangerous your mistake was.”
A excessive loss means the mannequin was very improper.
A low loss means the mannequin was shut.
Throughout coaching, the mannequin retains adjusting itself to make the loss smaller.
That’s how studying occurs. In case you have performed a dart recreation, it is rather related. You throw the dart. To enhance, you want suggestions. It’s worthwhile to know whether or not your dart was barely off, far-off, too excessive, or too far left. With out that suggestions, you can’t enhance. So, the bullseye is principally the right reply and the dart is the prediction. You measure the gap between the dart and the bullseye. The loss perform measures how far-off the dart landed. That distance turns into the mannequin’s suggestions sign. Here is how it could look when you favor a visualization.
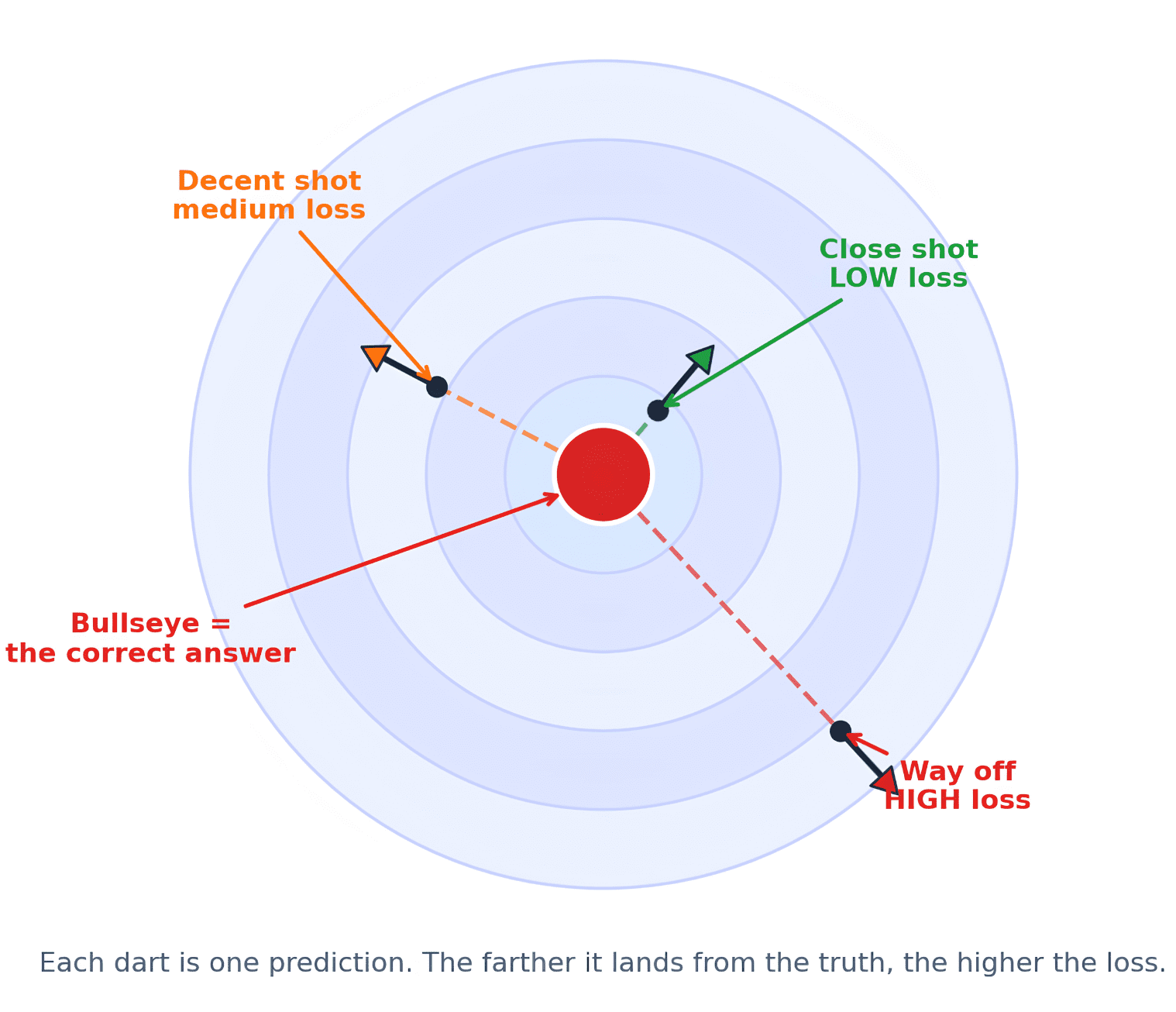
Identical to the gap from the middle issues, throwing too shut isn’t the identical as being method off. Equally, for fashions, simply understanding that the reply is improper isn’t sufficient. The mannequin must know the way badly it failed to be able to enhance.
Now that now we have an understanding of what a loss perform is and why we’d like it, let’s take a look at a number of the widespread loss capabilities utilized in machine studying.
# Imply Squared Error
The commonest loss for predicting numbers is imply squared error (MSE). It’s usually used when the mannequin is predicting numbers like home costs, temperatures, or supply occasions. The concept may be very easy.
- Error: For every prediction, take the hole between the guess and the reality.
- Squared: Multiply every hole by itself.
- Imply: Common all these squared gaps.
You possibly can write it in Python like this:
def mean_squared_error(predictions, actuals):
squared_errors = [(p - a) ** 2 for p, a in zip(predictions, actuals)]
return sum(squared_errors) / len(squared_errors)
Now, I do know that taking the errors after which averaging over the predictions is sensible intuitively, however understanding why we sq. them will be complicated. That is executed for 2 causes:
- Squaring makes each error constructive. An error of +3 and an error of -3 are equally dangerous, and squaring turns each into 9, in order that they cease cancelling one another out.
- Squaring punishes large errors much more harshly than small ones. That is good for plenty of use circumstances. For instance, if you’re predicting home costs, being improper by $1,000 versus $200,000 needs to be punished accordingly.
# Imply Absolute Error
One other widespread loss perform is imply absolute error (MAE). MAE additionally measures the hole between predictions and precise values, however it doesn’t sq. the error. As a substitute, it merely takes absolutely the worth.
Here is the Python perform to put in writing it:
def mean_absolute_error(predictions, actuals):
absolute_errors = [abs(p - a) for p, a in zip(predictions, actuals)]
return sum(absolute_errors) / len(absolute_errors)
So, it punishes giant errors, however not as harshly as MSE does.
- An error of 10 prices 10 and an error of 20 prices 20.
- In case your information naturally has some outliers and you don’t want your mannequin to overreact, MAE is an effective selection.
Let me present a fast graph that compares the MSE and MAE curves.

# Cross-Entropy Loss
To this point, now we have talked about predicting numbers. However many machine studying issues are about predicting classes.
Is that this electronic mail spam or not?
Is that this an image of a cat, canine, or fish?
Is a sure transaction fraudulent or not?
For classification duties, fashions normally output chances like:
Canine: 70%
Cat: 20%
Fish: 10%
If the picture actually is a canine, that could be a good prediction. But when it’s a cat, then the mannequin must be penalized for assigning a decrease chance to the right reply.
So, the instinct is:
- Right and assured — low loss
- Right however not sure — medium loss
- Fallacious and assured — excessive loss
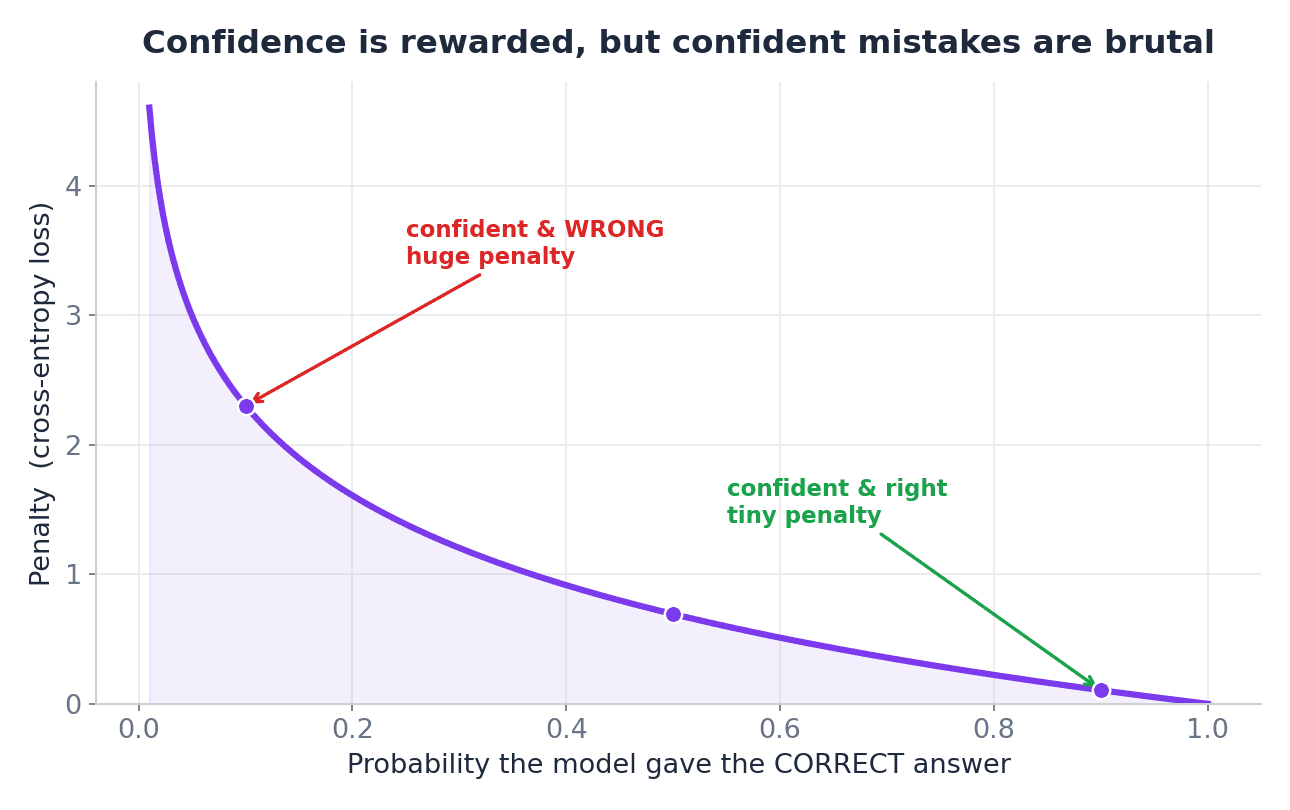
For this reason cross-entropy is so broadly used for classification. It doesn’t simply care about whether or not the mannequin was proper. It additionally cares about how assured the mannequin was.
# Loss vs. Accuracy
Now that now we have gone by means of totally different loss capabilities, I additionally need to make clear the distinction between loss and accuracy. They don’t seem to be the identical factor.
Accuracy tells you what number of predictions have been appropriate.
However loss tells you how dangerous the mannequin’s errors have been.
In case you have two fashions — Mannequin A and Mannequin B — and each get 90 out of 100 predictions appropriate, they are going to have the identical accuracy. However one mannequin could also be very assured on the precise solutions and solely barely improper on the inaccurate ones, whereas the opposite could also be barely appropriate on many examples and very assured when improper.
In that case, the accuracy can be the identical, however the loss can be totally different.
# The Coaching Loop
As soon as the mannequin has a loss quantity, it might probably enhance. The coaching loop appears like this:
- The mannequin makes predictions.
- The loss perform measures the errors.
- The optimizer updates the mannequin.
- The mannequin tries once more.
- The loss hopefully will get smaller.
When coaching a mannequin, we additionally plot the loss over time. At first, the mannequin makes many errors and is poor at making predictions, so the loss is excessive. However as coaching progresses, the loss decreases and the mannequin will get higher at making predictions.
A wholesome coaching curve usually appears like this:
Excessive loss at the beginning → sharp drop → gradual flattening
as you possibly can see within the determine under.

The flattening is regular. It means the mannequin has realized the straightforward patterns and is now making smaller enhancements. But when the coaching loss goes down whereas the validation loss begins going up, that may be a warning signal of overfitting — which suggests the mannequin could also be memorizing the coaching information as an alternative of studying patterns that generalize.
# Closing Ideas
A loss perform is the mannequin’s mistake rating.
It tells the mannequin how improper its predictions are, and it provides coaching a transparent purpose: make that quantity smaller.
When you perceive loss capabilities, many different machine studying concepts turn out to be simpler to understand — together with gradient descent, backpropagation, optimization, overfitting, and analysis metrics.
You do not want to start out with scary equations. Begin with the thought:
- The mannequin guesses.
- The loss perform scores the guess.
- The mannequin updates itself to cut back the rating.
That’s the coronary heart of machine studying.
Loss is how a mannequin is aware of it’s improper.
Coaching is the way it learns to be much less improper.
This brings us to the top of this text. We are going to proceed to cowl some fascinating ideas all through our noob collection.
Kanwal Mehreen is a machine studying engineer and a technical author with a profound ardour for information science and the intersection of AI with drugs. She co-authored the e-book “Maximizing Productiveness with ChatGPT”. As a Google Technology Scholar 2022 for APAC, she champions variety and tutorial excellence. She’s additionally acknowledged as a Teradata Range in Tech Scholar, Mitacs Globalink Analysis Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having based FEMCodes to empower ladies in STEM fields.