

{kind=link}
How can speech enhancing develop into as direct and controllable as merely rewriting a line of textual content? StepFun AI has open sourced Step-Audio-EditX, a 3B parameter LLM based mostly audio mannequin that turns expressive speech enhancing right into a token stage textual content like operation, as an alternative of a waveform stage sign processing process.
Why builders care about controllable TTS?
Most zero shot TTS techniques copy emotion, type, accent, and timbre immediately from a brief reference audio. They’ll sound pure, however management is weak. Model prompts in textual content assist just for in area voices, and the cloned voice usually ignores the requested emotion or talking type.
Previous work tries to disentangle elements with additional encoders, adversarial losses, or advanced architectures. Step-Audio-EditX retains a comparatively entangled illustration and as an alternative adjustments the info and put up coaching goal. The mannequin learns management by seeing many pairs and triplets the place textual content is fastened, however one attribute adjustments with a big margin.
Structure, twin codebook tokenizer plus compact audio LLM
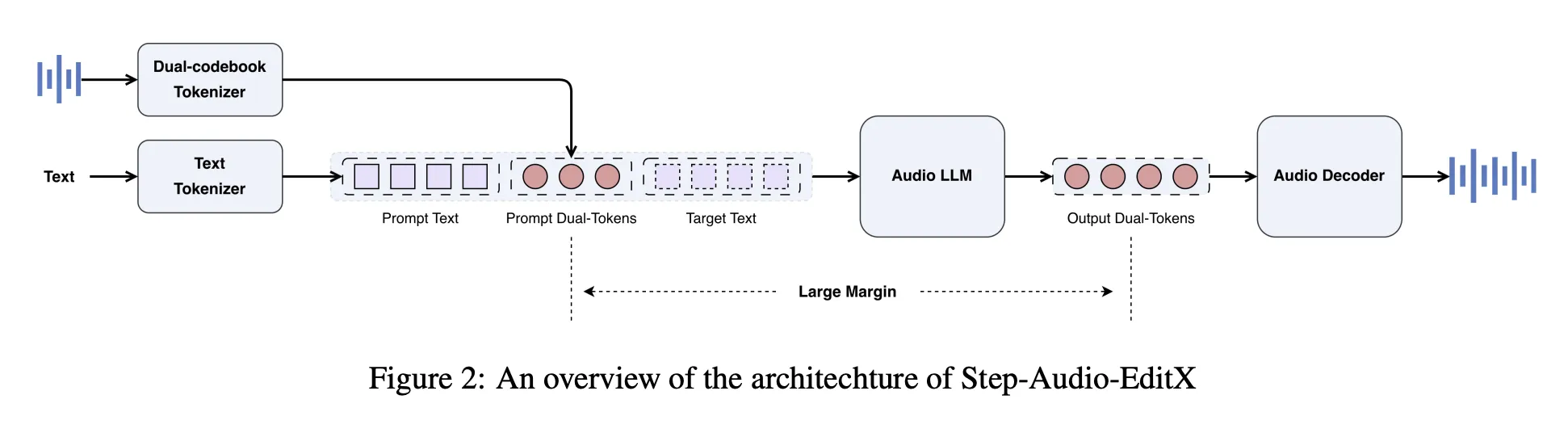
Step-Audio-EditX reuses the Step-Audio twin codebook tokenizer. Speech is mapped into two token streams, a linguistic stream at 16.7 Hz with a 1024 entry codebook, and a semantic stream at 25 Hz with a 4096 entry codebook. Tokens are interleaved with a 2 to three ratio. The tokenizer retains prosody and emotion data, so it isn’t absolutely disentangled.
On high of this tokenizer, the StepFun analysis group builds a 3B parameter audio LLM. The mannequin is initialized from a textual content LLM, then educated on a blended corpus with a 1 to 1 ratio of pure textual content and twin codebook audio tokens in chat type prompts. The audio LLM reads textual content tokens, audio tokens, or each, and at all times generates twin codebook audio tokens as output.
A separate audio decoder handles reconstruction. A diffusion transformer based mostly move matching module predicts Mel spectrograms from audio tokens, reference audio, and a speaker embedding, and a BigVGANv2 vocoder converts Mel spectrograms to waveform. The move matching module is educated on about 200000 hours of top quality speech, which improves pronunciation and timbre similarity.
Massive margin artificial knowledge as an alternative of difficult encoders
The important thing concept is massive margin studying. The mannequin is put up educated on triplets and quadruplets that hold textual content fastened and alter just one attribute with a transparent hole.
For zero shot TTS, Step-Audio-EditX makes use of a top quality in home dataset, primarily Chinese language and English, with a small quantity of Cantonese and Sichuanese, and about 60000 audio system. The information covers extensive intra speaker and inter speaker variation in type and emotion.(arXiv)
For emotion and talking type enhancing, the group builds artificial massive margin triplets (textual content, audio impartial, audio emotion or type). Voice actors report about 10 second clips for every emotion and magnificence. StepTTS zero shot cloning then produces impartial and emotional variations for a similar textual content and speaker. A margin scoring mannequin, educated on a small human labeled set, scores pairs on a 1 to 10 scale, and solely samples with rating not less than 6 are stored.
Paralinguistic enhancing, which covers respiratory, laughter, stuffed pauses and different tags, makes use of a semi artificial technique on high of the NVSpeech dataset. The analysis group builds quadruplets the place the goal is the unique NVSpeech audio and transcript, and the enter is a cloned model with tags faraway from the textual content. This offers time area enhancing supervision with out a margin mannequin.
Reinforcement studying knowledge makes use of two choice sources. Human annotators charge 20 candidates per immediate on a 5 level scale for correctness, prosody, and naturalness, and pairs with margin better than 3 are stored. A comprehension mannequin scores emotion and talking type on a 1 to 10 scale, and pairs with margin better than 8 are stored.
Submit coaching, SFT plus PPO on token sequences
Submit coaching has two phases, supervised nice tuning adopted by PPO.
In supervised nice tuning, system prompts outline zero shot TTS and enhancing duties in a unified chat format. For TTS, the immediate waveform is encoded to twin codebook tokens, transformed to string kind, and inserted into the system immediate as speaker data. The consumer message is the goal textual content, and the mannequin returns new audio tokens. For enhancing, the consumer message consists of authentic audio tokens plus a pure language instruction, and the mannequin outputs edited tokens.
Reinforcement studying then refines instruction following. A 3B reward mannequin is initialized from the SFT checkpoint and educated with Bradley Terry loss on massive margin choice pairs. The reward is computed immediately on twin codebook token sequences, with out decoding to waveform. PPO coaching makes use of this reward mannequin, a clip threshold, and a KL penalty to steadiness high quality and deviation from the SFT coverage.
Step-Audio-Edit-Check, iterative enhancing and generalization
To quantify management, the analysis group launched Step-Audio-Edit-Check. It makes use of Gemini 2.5 Professional as an LLM as a decide to guage emotion, talking type, and paralinguistic accuracy. The benchmark has 8 audio system, drawn from Wenet Speech4TTS, GLOBE V2, and Libri Mild, with 4 audio system per language.
The emotion set has 5 classes with 50 Chinese language and 50 English prompts per class. The talking type set has 7 kinds with 50 prompts per language per type. The paralinguistic set has 10 labels resembling respiratory, laughter, shock oh, and uhm, with 50 prompts per label and language.
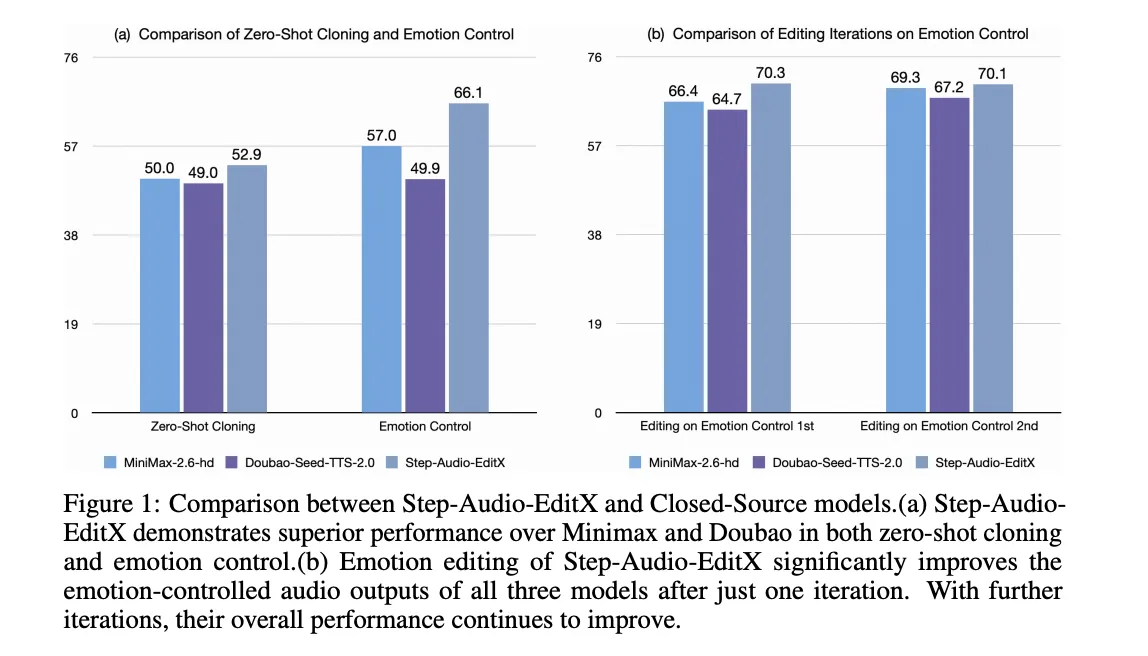
Enhancing is evaluated iteratively. Iteration 0 is the preliminary zero shot clone. Then the mannequin applies 3 rounds of enhancing with textual content directions. In Chinese language, emotion accuracy rises from 57.0 at iteration 0 to 77.7 at iteration 3. Talking type accuracy rises from 41.6 to 69.2. English reveals related habits, and a immediate fastened ablation, the place the identical immediate audio is used for all iterations, nonetheless improves accuracy, which helps the big margin studying speculation.

The identical enhancing mannequin is utilized to 4 closed supply TTS techniques, GPT 4o mini TTS, ElevenLabs v2, Doubao Seed TTS 2.0, and MiniMax speech 2.6 hd. For all of them, one enhancing iteration with Step-Audio-EditX improves each emotion and magnificence accuracy, and additional iterations proceed to assist.
Paralinguistic enhancing is scored on a 1 to three scale. The common rating rises from 1.91 at iteration 0 to 2.89 after a single edit, in each Chinese language and English, which is corresponding to native paralinguistic synthesis in robust business techniques.

Key Takeaways
- Step Audio EditX makes use of a twin codebook tokenizer and a 3B parameter audio LLM so it will possibly deal with speech as discrete tokens and edit audio in a textual content like approach.
- The mannequin depends on massive margin artificial knowledge for emotion, talking type, paralinguistic cues, pace, and noise, somewhat than including additional disentangling encoders.
- Supervised nice tuning plus PPO with a token stage reward mannequin aligns the audio LLM to comply with pure language enhancing directions for each TTS and enhancing duties.
- The Step Audio Edit Check benchmark with Gemini 2.5 Professional as a decide reveals clear accuracy positive aspects over 3 enhancing iterations for emotion, type, and paralinguistic management in each Chinese language and English.
- Step Audio EditX can put up course of and enhance speech from closed supply TTS techniques, and the total stack, together with code and checkpoints, is accessible as open supply for builders.
Step Audio EditX is a exact step ahead in controllable speech synthesis, as a result of it retains the Step Audio tokenizer, provides a compact 3B audio LLM, and optimizes management by means of massive margin knowledge and PPO. The introduction of Step Audio Edit Check with Gemini 2.5 Professional as a decide makes the analysis story concrete for emotion, talking type, and paralinguistic management, and the open launch lowers the barrier for sensible audio enhancing analysis. Total, this launch makes audio enhancing really feel a lot nearer to textual content enhancing.
Take a look at the Paper, Repo and Mannequin Weights. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as nicely.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.