

{kind=link}
How can groups run trillion parameter language fashions on current blended GPU clusters with out expensive new {hardware} or deep vendor lock in? Perplexity’s analysis workforce has launched TransferEngine and the encircling pplx backyard toolkit as open supply infrastructure for giant language mannequin programs. This gives a strategy to run fashions with as much as 1 trillion parameters throughout blended GPU clusters, with out locking right into a single cloud supplier or shopping for new GB200 class {hardware}.
The true bottleneck, community materials not FLOPs
Fashionable deployments of Combination of Specialists fashions corresponding to DeepSeek V3 with 671 billion parameters and Kimi K2 with 1 trillion parameters now not match on a single 8 GPU server. They need to span a number of nodes, so the primary constraint turns into the community material between GPUs.
Right here the {hardware} panorama is fragmented. NVIDIA ConnectX 7 usually makes use of Dependable Connection transport with so as supply. AWS Elastic Cloth Adapter makes use of Scalable Dependable Datagram transport that’s dependable however out of order, and a single GPU might have 4 community adapters at 100 Gbps, or 2 at 200 Gbps, to succeed in 400 Gbps.
Current libraries corresponding to DeepEP, NVSHMEM, MoonCake and NIXL are inclined to optimize for one vendor and degrade or lack help on the opposite aspect. Perplexity’s analysis workforce straight states within the analysis paper that there was no viable cross supplier answer for LLM inference earlier than this work.
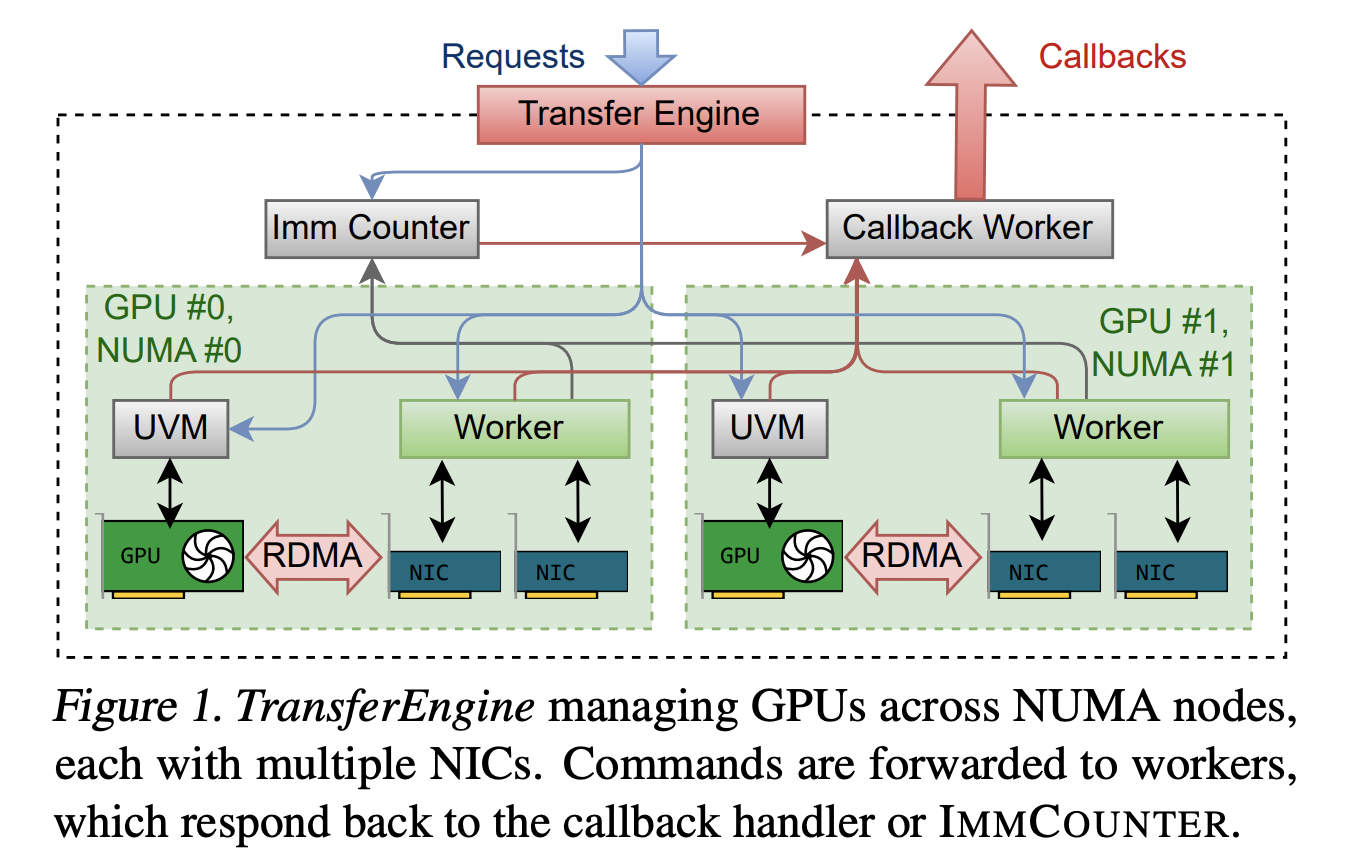
TransferEngine, a conveyable RDMA layer for LLM programs
TransferEngine addresses this by concentrating on solely the intersection of ensures throughout Community Interface Controllers. It assumes that the underlying RDMA transport is dependable, however doesn’t assume any ordering of messages. On high of this, it exposes one sided WriteImm operations and an ImmCounter primitive for completion notification.
The library gives a minimal API in Rust. It presents two sided Ship and Recv for management messages, and three most important one sided operations, submit_single_write, submit_paged_writes, and submit_scatter, plus a submit_barrier primitive for synchronization throughout a bunch of friends. A NetAddr construction identifies friends and an MrDesc construction describes registered reminiscence areas. An alloc_uvm_watcher name creates a tool aspect watcher for CPU GPU synchronization in superior pipelines.
Internally, TransferEngine spawns one employee thread per GPU and builds a DomainGroup per GPU that coordinates between 1 and 4 RDMA Community Interface Controllers. A single ConnectX 7 gives 400 Gbps. On EFA, the DomainGroup aggregates 4 community adapters at 100 Gbps, or 2 at 200 Gbps, to succeed in the identical bandwidth. The sharding logic is aware of about all Community Interface Controllers and may break up a switch throughout them.
Throughout {hardware}, the analysis workforce studies peak throughput of 400 Gbps on each NVIDIA ConnectX 7 and AWS EFA. This matches single platform options and confirms that the abstraction layer doesn’t go away giant efficiency on the desk.

pplx backyard, the open supply bundle
TransferEngine ships as a part of the pplx backyard repository on GitHub underneath an MIT license. The listing construction is simple. fabric-lib accommodates the RDMA TransferEngine library, p2p-all-to-all implements a Combination of Specialists all to all kernel, python-ext gives the Python extension module from the Rust core, and python/pplx_garden accommodates the Python bundle code.
The system necessities replicate a contemporary GPU cluster. Perplexity analysis workforce recommends Linux kernel 5.12 or newer for DMA BUF help, CUDA 12.8 or newer, libfabric, libibverbs, GDRCopy, and an RDMA material with GPUDirect RDMA enabled. Every GPU ought to have at the very least one devoted RDMA Community Interface Controller.
Disaggregated prefill and decode
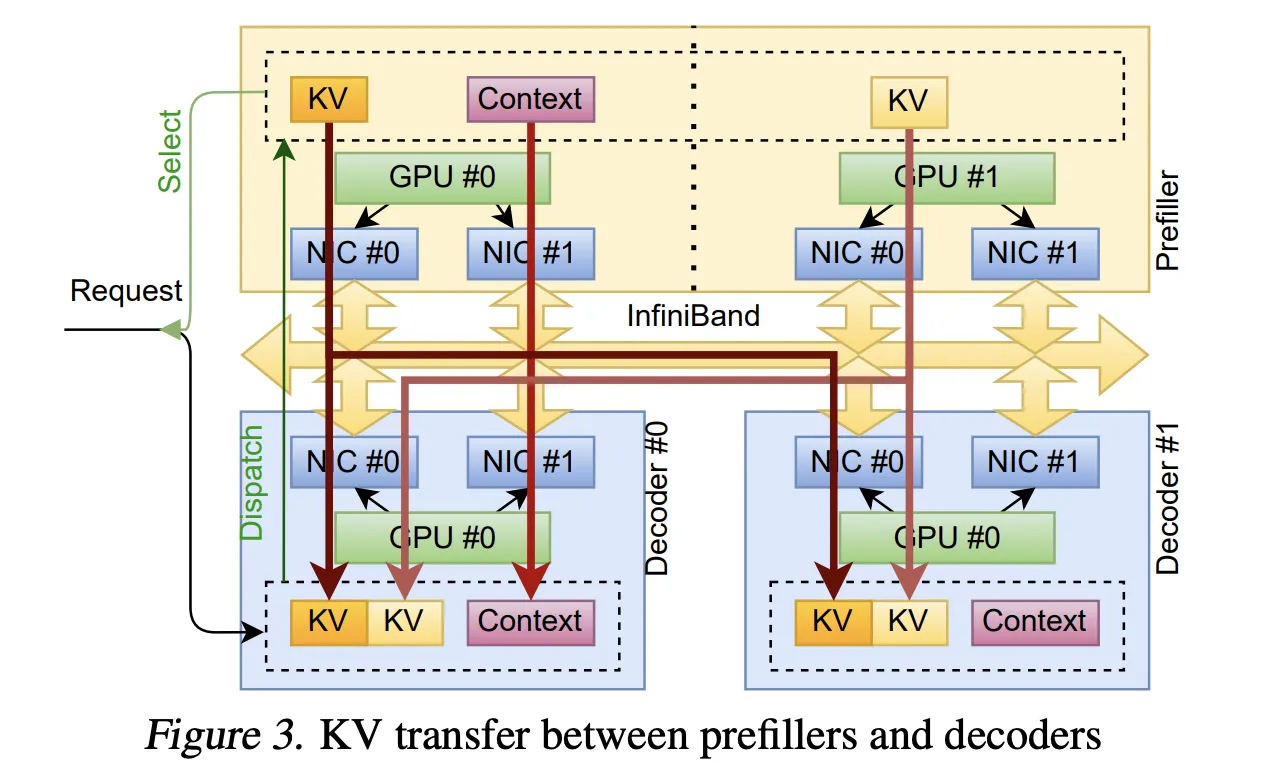
The first manufacturing use case is disaggregated inference. Prefill and decode run on separate clusters, so the system should stream KvCache from prefill GPUs to decode GPUs at excessive velocity.
TransferEngine makes use of alloc_uvm_watcher to trace progress within the mannequin. Throughout prefill, the mannequin increments a watcher worth after every layer’s consideration output projection. When the employee observes a change, it points paged writes for the KvCache pages of that layer, adopted by a single write for the remaining context. This method permits layer by layer streaming of cache pages with out fastened world membership, and it avoids the strict ordering constraints of collectives.
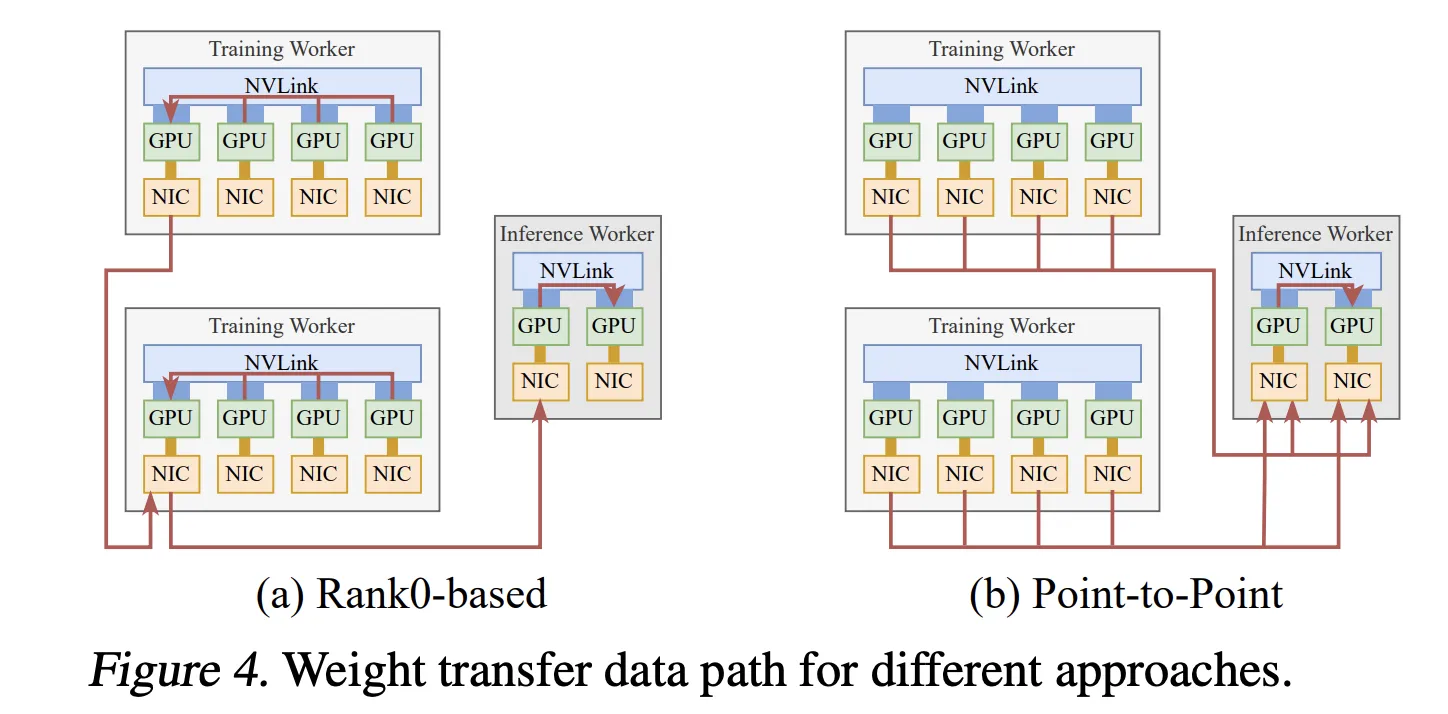
Quick weight switch for reinforcement studying
The second system is asynchronous reinforcement studying superb tuning, the place coaching and inference run on separate GPU swimming pools. Conventional designs collect up to date parameters to a single rank then broadcast them, which limits throughput to 1 Community Interface Controller.
Perplexity analysis workforce as a substitute makes use of TransferEngine to carry out level to level weight switch. Every coaching GPU writes its parameter shard straight into the corresponding inference GPUs utilizing one sided writes. A pipelined execution splits every tensor into levels, host to machine copy when Absolutely Sharded Information Parallel offloads weights, reconstruction and optionally available quantization, RDMA switch, and a barrier carried out via scatter and ImmCounter.
In manufacturing, this setup delivers weight updates for fashions corresponding to Kimi K2 at 1 trillion parameters and DeepSeek V3 at 671 billion parameters in about 1.3 seconds from 256 coaching GPUs to 128 inference GPUs.
Combination of Specialists routing throughout ConnectX and EFA
The third piece in pplx backyard is some extent to level Combination of Specialists dispatch and mix kernel. It makes use of NVLink for intra node visitors and RDMA for inter node visitors. Dispatch and mix are break up into separate ship and obtain phases in order that the decoder can micro batch and overlap communication with grouped basic matrix multiply.
A bunch proxy thread polls GPU state and calls TransferEngine when ship buffers are prepared. Routes are exchanged first, then every rank computes contiguous obtain offsets for every knowledgeable and writes tokens into non-public buffers that may be reused between dispatch and mix. This reduces reminiscence footprint and retains writes giant sufficient to make use of the complete hyperlink bandwidth.
On ConnectX 7, Perplexity analysis workforce studies state-of-the-art decode latency that’s aggressive with DeepEP throughout knowledgeable counts. On AWS EFA, the identical kernel delivers the primary viable MoE decode latencies with greater however nonetheless sensible values.
In multi node checks with DeepSeek V3 and Kimi K2 on AWS H200 situations, distributing the mannequin throughout nodes reduces latency at medium batch sizes, which is the widespread regime for manufacturing serving.
Comparability Desk
| Key level | TransferEngine (pplx backyard) | DeepEP | NVSHMEM (generic MoE use) | Mooncake |
|---|---|---|---|---|
| Main position | Moveable RDMA level to level for LLM programs | MoE all to all dispatch and mix | Normal GPU shared reminiscence and collectives | Distributed KV cache for LLM inference |
| {Hardware} focus | NVIDIA ConnectX 7 and AWS EFA, multi NIC per GPU | NVIDIA ConnectX with GPU initiated RDMA IBGDA | NVIDIA GPUs on RDMA materials together with EFA | RDMA NICs in KV centric serving stacks |
| EFA standing | Full help, peak 400 Gbps reported | No help, requires IBGDA on ConnectX | API works however MoE use exhibits extreme degradation on EFA | Paper studies no EFA help in its RDMA engine |
| Portability for LLM programs | Cross vendor, single API throughout ConnectX 7 and EFA | Vendor particular and ConnectX centered | NVIDIA centric, not viable for EFA MoE routing | Targeted on KV sharing, no cross supplier help |
Key Takeaways
- TransferEngine provides a single RDMA level to level abstraction that works on each NVIDIA ConnectX 7 and AWS EFA, and manages a number of Community Interface Controllers per GPU transparently.
- The library exposes one sided WriteImm with ImmCounter, and achieves peak 400 Gbps throughput on each NIC households, which lets it match single vendor stacks whereas remaining transportable.
- Perplexity workforce makes use of TransferEngine in three manufacturing programs, disaggregated prefill decode with KvCache streaming, reinforcement studying weight switch that updates trillion parameter fashions in about 1.3 seconds, and Combination of Specialists dispatch mix for giant fashions like Kimi K2.
- On ConnectX 7, pplx backyard’s MoE kernels present state-of-the-art decode latency and exceed DeepEP on the identical {hardware}, whereas on EFA they ship the primary sensible MoE latencies for trillion parameter workloads.
- As a result of TransferEngine is open supply in pplx backyard underneath an MIT license, groups can run very giant Combination of Specialists and dense fashions on heterogeneous H100 or H200 clusters throughout cloud suppliers, with out rewriting for every vendor particular networking stack.
Perplexity’s launch of TransferEngine and pplx backyard is a sensible contribution for LLM infra groups who’re blocked by vendor particular networking stacks and costly material upgrades. A conveyable RDMA abstraction that reaches peak 400 Gbps on each NVIDIA ConnectX 7 and AWS EFA, helps KvCache streaming, quick reinforcement studying weight switch, and Combination of Specialists routing, straight addresses trillion parameter serving constraints for actual programs.
Try the Paper and Repo. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.