

{kind=link}
How can we design AI methods that may plan, purpose, and act over lengthy sequences of selections with out fixed human steerage? Moonshot AI has launched Kimi K2 Considering, an open supply pondering agent mannequin that exposes the total reasoning stream of the Kimi K2 Combination of Specialists structure. It targets workloads that want deep reasoning, lengthy horizon device use, and steady agent habits throughout many steps.
What’s Kimi K2 Considering?
Kimi K2 Considering is described as the newest, most succesful model of Moonshot’s open supply pondering mannequin. It’s constructed as a pondering agent that causes step-by-step and dynamically invokes instruments throughout inference. The mannequin is designed to interleave chain of thought with operate calls so it may possibly learn, suppose, name a device, suppose once more, and repeat for a whole lot of steps.
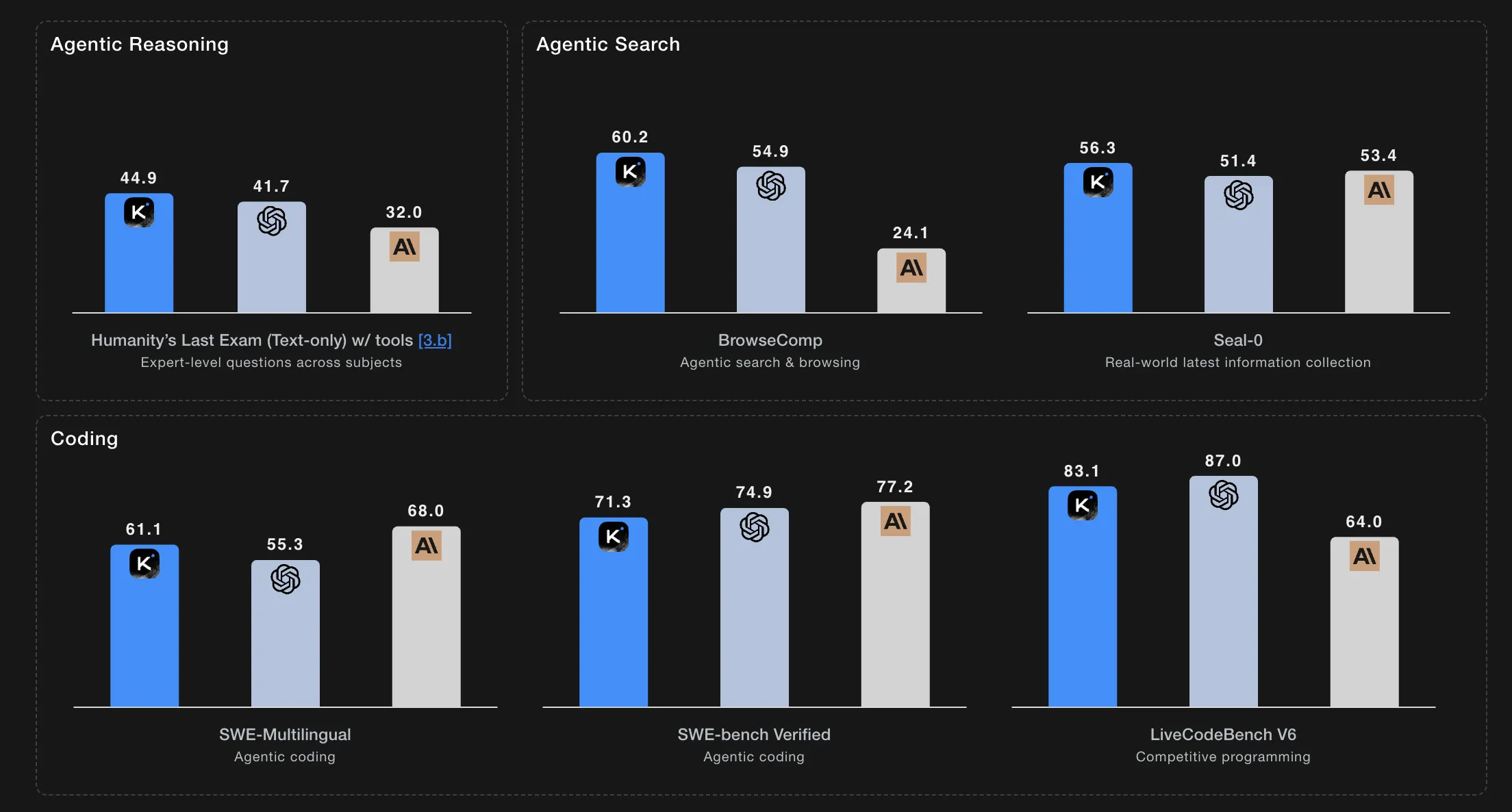
The mannequin units a brand new state-of-the-art on Humanity’s Final Examination and BrowseComp, whereas sustaining coherent habits throughout about 200 to 300 sequential device calls with out human interference.
On the similar time, K2 Considering is launched as an open weights mannequin with a 256K token context window and native INT4 inference, which reduces latency and GPU reminiscence utilization whereas preserving benchmark efficiency.
K2 Considering is already reside on kimi.com in chat mode and is accessible by means of the Moonshot platform API, with a devoted agentic mode deliberate to reveal the total device utilizing habits.
Structure, MoE design, and context size
Kimi K2 Considering inherits the Kimi K2 Combination of Specialists design. The mannequin makes use of a MoE structure with 1T whole parameters and 32B activated parameters per token. It has 61 layers together with 1 dense layer, 384 specialists with 8 specialists chosen per token, 1 shared professional, 64 consideration heads, and an consideration hidden dimension of 7168. The MoE hidden dimension is 2048 per professional.
The vocabulary dimension is 160K tokens and the context size is 256K. The eye mechanism is Multi head Latent Consideration, and the activation operate is SwiGLU.
Take a look at time scaling and lengthy horizon pondering
Kimi K2 Considering is explicitly optimized for check time scaling. The mannequin is skilled to broaden its reasoning size and gear name depth when going through tougher duties, fairly than counting on a set quick chain of thought.
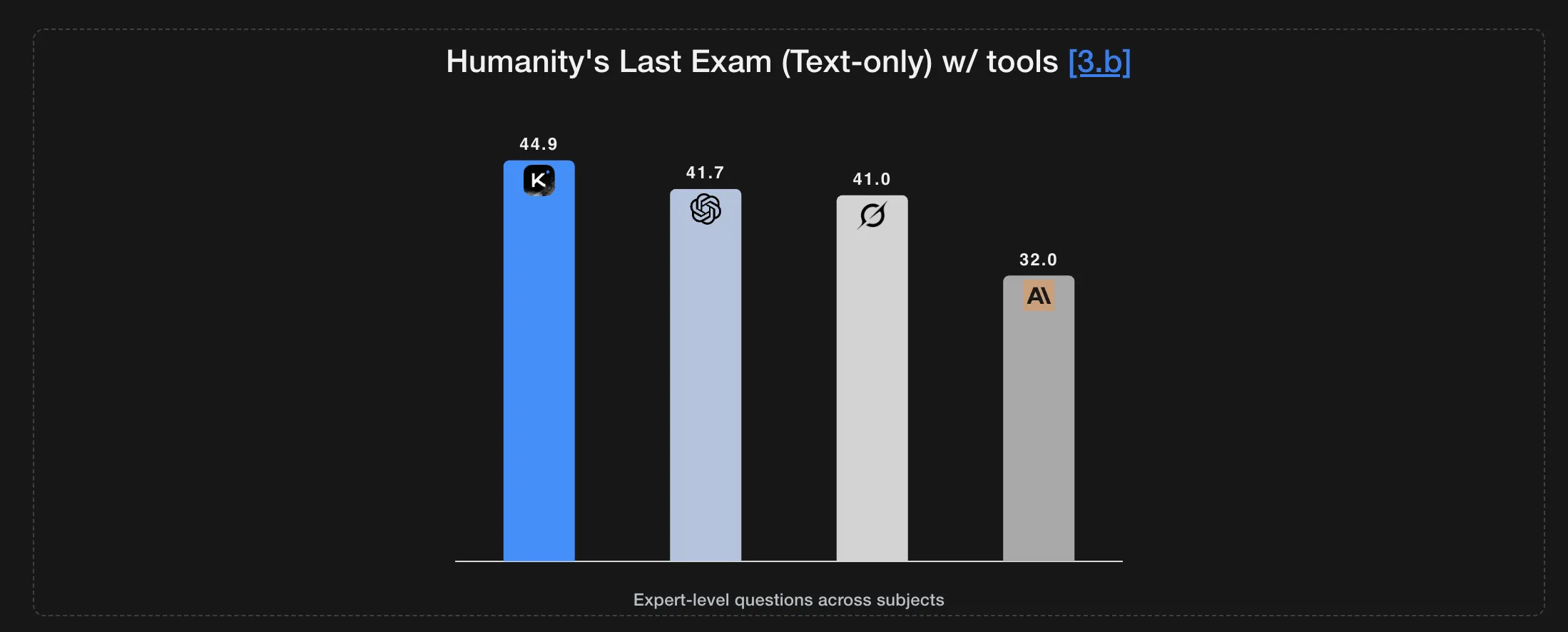
On Humanity’s Final Examination within the no instruments setting, K2 Considering scores 23.9. With instruments, the rating rises to 44.9, and within the heavy setting it reaches 51.0. On AIME25 with Python, it reviews 99.1, and on HMMT25 with Python it reviews 95.1. On IMO AnswerBench it scores 78.6, and on GPQA it scores 84.5.
The testing protocol caps pondering token budgets at 96K for HLE, AIME25, HMMT25, and GPQA. It makes use of 128K pondering tokens for IMO AnswerBench, LiveCodeBench, and OJ Bench, and 32K completion tokens for Longform Writing. On HLE, the utmost step restrict is 120 with a 48K reasoning finances per step. On agentic search duties, the restrict is 300 steps with a 24K reasoning finances per step.
Benchmarks in agentic search and coding
On agentic search duties with instruments, K2 Considering reviews 60.2 on BrowseComp, 62.3 on BrowseComp ZH, 56.3 on Seal 0, 47.4 on FinSearchComp T3, and 87.0 on Frames.
On basic data benchmarks, it reviews 84.6 on MMLU Professional, 94.4 on MMLU Redux, 73.8 on Longform Writing, and 58.0 on HealthBench.
For coding, K2 Considering achieves 71.3 on SWE bench Verified with instruments, 61.1 on SWE bench Multilingual with instruments, 41.9 on Multi SWE bench with instruments, 44.8 on SciCode, 83.1 on LiveCodeBenchV6, 48.7 on OJ Bench within the C plus plus setting, and 47.1 on Terminal Bench with simulated instruments.
Moonshot staff additionally defines a Heavy Mode that runs eight trajectories in parallel, then aggregates them to supply a remaining reply. That is utilized in some reasoning benchmarks to squeeze out further accuracy from the identical base mannequin.
Native INT4 quantization and deployment
K2 Considering is skilled as a local INT4 mannequin. The analysis staff applies Quantization Conscious Coaching through the submit coaching stage and makes use of INT4 weight solely quantization on the MoE parts. This helps INT4 inference with roughly a 2x era velocity enchancment in low latency mode whereas sustaining state-of-the-art efficiency. All reported benchmark scores are obtained underneath INT4 precision.
The checkpoints are saved in compressed tensors format and might be unpacked to greater precision codecs reminiscent of FP8 or BF16 utilizing the official compressed tensors instruments. Beneficial inference engines embody vLLM, SGLang, and KTransformers.
Key Takeaways
- Kimi K2 Considering is an open weights pondering agent that extends the Kimi K2 Combination of Specialists structure with specific lengthy horizon reasoning and gear use, not simply quick chat model responses.
- The mannequin makes use of a trillion parameter MoE design with about tens of billions of lively parameters per token, a 256K context window, and is skilled as a local INT4 mannequin with Quantization Conscious Coaching, which supplies about 2x sooner inference whereas maintaining benchmark efficiency steady.
- K2 Considering is optimized for check time scaling, it may possibly perform a whole lot of sequential device calls in a single process and is evaluated underneath giant pondering token budgets and strict step caps, which is vital if you attempt to reproduce its reasoning and agentic outcomes.
- On public benchmarks, it leads or is aggressive on reasoning, agentic search, and coding duties reminiscent of HLE with instruments, BrowseComp, and SWE bench Verified with instruments, exhibiting that the pondering oriented variant delivers clear positive factors over the bottom non pondering K2 mannequin.
Kimi K2 Considering is a robust sign that check time scaling is now a firstclass design goal for open supply reasoning fashions. Moonshot AI will not be solely exposing a 1T parameter Combination of Specialists system with 32B lively parameters and 256K context window, it’s doing so with native INT4 quantization, Quantization Conscious Coaching, and gear orchestration that runs for a whole lot of steps in manufacturing like settings. General, Kimi K2 Considering exhibits that open weights reasoning brokers with lengthy horizon planning and gear use have gotten sensible infrastructure, not simply analysis demos.
Try the Mannequin Weights and Technical Particulars. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.