

{kind=link}
Microsoft has introduced the discharge of Harrier-OSS-v1, a household of three multilingual textual content embedding fashions designed to offer high-quality semantic representations throughout a variety of languages. The discharge contains three distinct scales: a 270M parameter mannequin, a 0.6B mannequin, and a 27B mannequin.
The Harrier-OSS-v1 fashions achieved state-of-the-art (SOTA) outcomes on the Multilingual MTEB (Huge Textual content Embedding Benchmark) v2. For AI professionals, this launch marks a big milestone in open-source retrieval know-how, providing a scalable vary of fashions that leverage trendy LLM architectures for embedding duties.
Structure and Basis
The Harrier-OSS-v1 household strikes away from the normal bidirectional encoder architectures (akin to BERT) which have dominated the embedding panorama for years. As an alternative, these fashions make the most of decoder-only architectures, just like these present in trendy Giant Language Fashions (LLMs).
The usage of decoder-only foundations represents a shift in how context is processed. In a causal (decoder-only) mannequin, every token can solely attend to the tokens that come earlier than it. To derive a single vector representing your entire enter, Harrier makes use of last-token pooling. This implies the hidden state of the final token within the sequence is used as the mixture illustration of the textual content, which is then subjected to L2 normalization to make sure the vector has a constant magnitude.
Technical Specs
The Harrier-OSS-v1 fashions are characterised by their various embedding dimensions and their constant assist for long-context inputs. The next desk gives a breakdown of the technical specs:
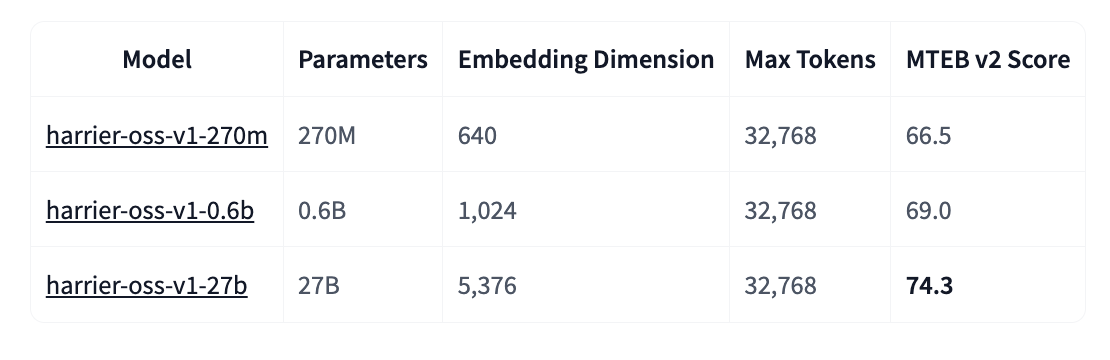
The 32,768 (32k) token context window throughout all three sizes is a big characteristic for Retrieval-Augmented Technology (RAG) programs. Most conventional embedding fashions are restricted to 512 or 1,024 tokens. The expanded window permits AI devs to embed considerably bigger paperwork or code recordsdata with out the necessity for aggressive chunking, which regularly leads to a lack of semantic coherence.
Implementation: Instruction-Primarily based Embeddings
Probably the most necessary operational particulars for AI devs is that Harrier-OSS-v1 is an instruction-tuned embedding household. To realize the benchmarked efficiency, the mannequin requires task-specific directions to be supplied on the time of the question.
The implementation follows a selected logic:
- Question-side: All queries needs to be prepended with a one-sentence process instruction that defines the intent (e.g., retrieving semantically comparable textual content or discovering a translation).
- Doc-side: Paperwork needs to be encoded with out directions.
An instance question format would seem like this:
"Instruct: Retrieve semantically comparable textnQuery: [User input text]"This instruction-based method permits the mannequin to regulate its vector area dynamically primarily based on the duty, bettering retrieval accuracy throughout completely different domains akin to net search or bitext mining.
Coaching and Data Distillation
The event of the Harrier-OSS-v1 household concerned a multi-stage coaching course of. Whereas the 27B mannequin gives the best parameter rely and dimensionality (5,376), Microsoft workforce utilized specialised methods to spice up the efficiency of the smaller variants.
The 270M and 0.6B fashions have been moreover skilled utilizing information distillation from bigger embedding fashions. Data distillation is a method the place a ‘pupil’ mannequin is skilled to copy the output distributions or characteristic representations of a high-performance ‘trainer’ mannequin. This course of permits the smaller Harrier fashions to realize larger embedding high quality than would sometimes be anticipated from their parameter counts, making them extra environment friendly for deployments the place reminiscence or latency is an element.
Efficiency on Multilingual MTEB v2
The Multilingual MTEB v2 is a complete benchmark that evaluates fashions throughout various duties, together with:
- Classification: Figuring out the class of a textual content.
- Clustering: Grouping comparable paperwork.
- Pair Classification: Figuring out if two sentences are paraphrases.
- Retrieval: Discovering probably the most related doc for a given question.
By reaching SOTA outcomes on this benchmark at launch, the Harrier household demonstrates a excessive stage of proficiency in cross-lingual retrieval. That is significantly beneficial for international functions the place a system might have to course of queries and paperwork in numerous languages throughout the similar vector area.
Key Takeaways
- Scalable Multilingual SOTA: The household contains three fashions (270M, 0.6B, and 27B) that achieved State-of-the-Artwork outcomes on the Multilingual MTEB v2 benchmark as of their launch date.
- Decoder-Solely Basis: Transferring away from BERT-style encoders, these fashions use decoder-only architectures with last-token pooling and L2 normalization.
- Expanded 32k Context: All fashions assist a 32,768-token context window, permitting for the illustration of long-form paperwork or codebases with out the semantic loss related to aggressive chunking.
- Instruction-Dependent Retrieval: Finest efficiency requires query-side directions (a one-sentence process description prepended to the enter), whereas paperwork needs to be encoded with none directions.
- High quality through Distillation: The smaller 270M (640-dim) and 0.6B (1,024-dim) fashions have been skilled utilizing information distillation from bigger embedding fashions to enhance their semantic illustration high quality relative to their parameter counts.
Take a look at the Mannequin Weights right here. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be part of us on telegram as properly.