

{kind=link}
How do you design an LLM agent that decides for itself what to retailer in long run reminiscence, what to maintain in brief time period context and what to discard, with out hand tuned heuristics or further controllers? Can a single coverage be taught to handle each reminiscence sorts via the identical motion house as textual content technology?
Researchers from Alibaba Group and Wuhan College introduce Agentic Reminiscence, or AgeMem, a framework that lets massive language mannequin brokers discover ways to handle each long run and brief time period reminiscence as a part of a single coverage. As an alternative of relying readily available written guidelines or exterior controllers, the agent decides when to retailer, retrieve, summarize and overlook, utilizing reminiscence instruments which might be built-in into the motion house of the mannequin.
Why present LLM brokers battle with reminiscence
Most agent frameworks deal with reminiscence as two loosely coupled programs.
Long run reminiscence shops person profiles, job info and former interactions throughout classes. Brief time period reminiscence is the present context window, which holds the lively dialogue and retrieved paperwork.
Present programs design these two components in isolation. Long run reminiscence is dealt with via exterior shops akin to vector databases with easy add and retrieve triggers. Brief time period reminiscence is managed with retrieval augmented technology, sliding home windows or summarization schedules.
This separation creates a number of points.
- Long run and brief time period reminiscence are optimized independently. Their interplay is just not educated finish to finish.
- Heuristics determine when to jot down to reminiscence and when to summarize. These guidelines are brittle and miss uncommon however essential occasions.
- Further controllers or skilled fashions enhance value and system complexity.
AgeMem removes the exterior controller and folds reminiscence operations into the agent coverage itself.
Reminiscence as instruments within the agent motion house
In AgeMem, reminiscence operations are uncovered as instruments. At every step, the mannequin can emit both regular textual content tokens or a instrument name. The framework defines 6 instruments.
For long run reminiscence:
ADDshops a brand new reminiscence merchandise with content material and metadata.UPDATEmodifies an current reminiscence entry.DELETEremoves out of date or low worth objects.
For brief time period reminiscence:
RETRIEVEperforms semantic search over long run reminiscence and injects the retrieved objects into the present context.SUMMARYcompresses spans of the dialogue into shorter summaries.FILTERremoves context segments that aren’t helpful for future reasoning.
The interplay protocol has a structured format. Every step begins with a
Three stage reinforcement studying for unified reminiscence
AgeMem is educated with reinforcement studying in a means that {couples} long run and brief time period reminiscence conduct.
The state at time t consists of the present conversational context, the long run reminiscence retailer and the duty specification. The coverage chooses both a token or a instrument name because the motion. The coaching trajectory for every pattern is split into 3 levels:
- Stage 1, long run reminiscence building: The agent interacts in an informal setting and observes info that may later turn out to be related. It makes use of
ADD,UPDATEandDELETEto construct and keep long run reminiscence. The brief time period context grows naturally throughout this stage. - Stage 2, brief time period reminiscence management underneath distractors: The brief time period context is reset. Long run reminiscence persists. The agent now receives distractor content material that’s associated however not mandatory. It should handle brief time period reminiscence utilizing
SUMMARYandFILTERto maintain helpful content material and take away noise. - Stage 3, built-in reasoning: The ultimate question arrives. The agent retrieves from long run reminiscence utilizing
RETRIEVE, controls the brief time period context, and produces the reply.
The essential element is that long run reminiscence persists throughout all levels whereas brief time period reminiscence is cleared between Stage 1 and Stage 2. This design forces the mannequin to depend on retrieval fairly than on residual context and exposes life like lengthy horizon dependencies.
Reward design and step clever GRPO
AgeMem makes use of a step clever variant of Group Relative Coverage Optimization (GRPO). For every job, the system samples a number of trajectories that kind a bunch. A terminal reward is computed for every trajectory, then normalized inside the group to acquire a bonus sign. This benefit is broadcast to all steps within the trajectory in order that intermediate instrument selections are educated utilizing the ultimate consequence.
The overall reward has three primary parts:
- A job reward that scores reply high quality between 0 and 1 utilizing an LLM choose.
- A context reward that measures the standard of brief time period reminiscence operations, together with compression, early summarization and preservation of question related content material.
- A reminiscence reward that measures long run reminiscence high quality, together with the fraction of top of the range saved objects, the usefulness of upkeep operations and the relevance of retrieved objects to the question.
Uniform weights are used for these three parts so that every contributes equally to the educational sign. A penalty time period is added when the agent exceeds the utmost allowed dialogue size or when the context overflows the restrict.
Experimental setup and primary outcomes
The analysis workforce fine-tune AgeMem on the HotpotQA coaching break up and consider on 5 benchmarks:
- ALFWorld for textual content based mostly embodied duties.
- SciWorld for science themed environments.
- BabyAI for instruction following.
- PDDL duties for planning.
- HotpotQA for multi hop query answering.
Metrics embody success price for ALFWorld, SciWorld and BabyAI, progress price for PDDL duties, and an LLM choose rating for HotpotQA. In addition they outline a Reminiscence High quality metric utilizing an LLM evaluator that compares saved reminiscences to the supporting information of HotpotQA.
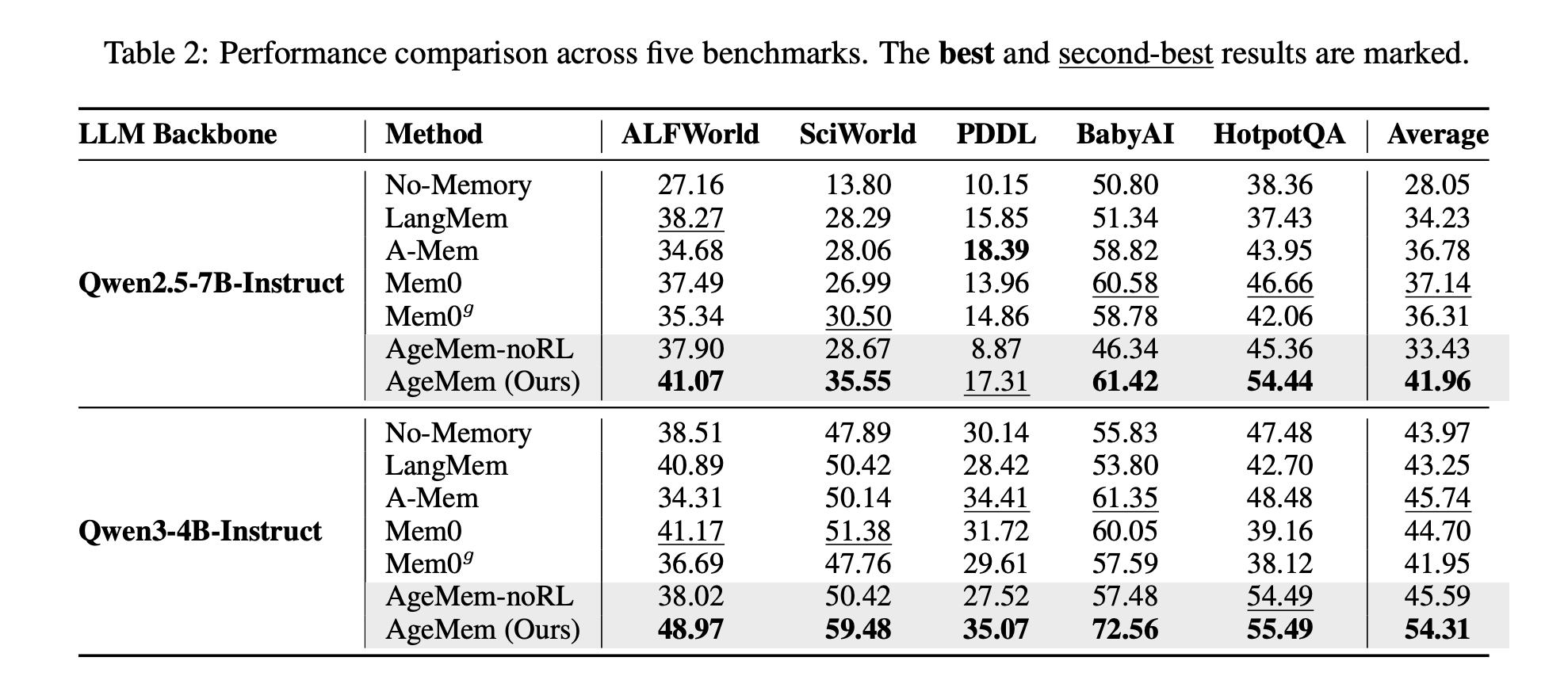
Baselines embody LangMem, A Mem, Mem0, Mem0g and a no reminiscence agent. Backbones are Qwen2.5-7B-Instruct and Qwen3-4B-Instruct.
On Qwen2.5-7B-Instruct, AgeMem reaches a mean rating of 41.96 throughout the 5 benchmarks, whereas the most effective baseline, Mem0, reaches 37.14. On Qwen3-4B-Instruct, AgeMem reaches 54.31, in comparison with 45.74 for the most effective baseline, A Mem.
Reminiscence high quality additionally improves. On HotpotQA, AgeMem reaches 0.533 with Qwen2.5-7B and 0.605 with Qwen3-4B, which is increased than all baselines.
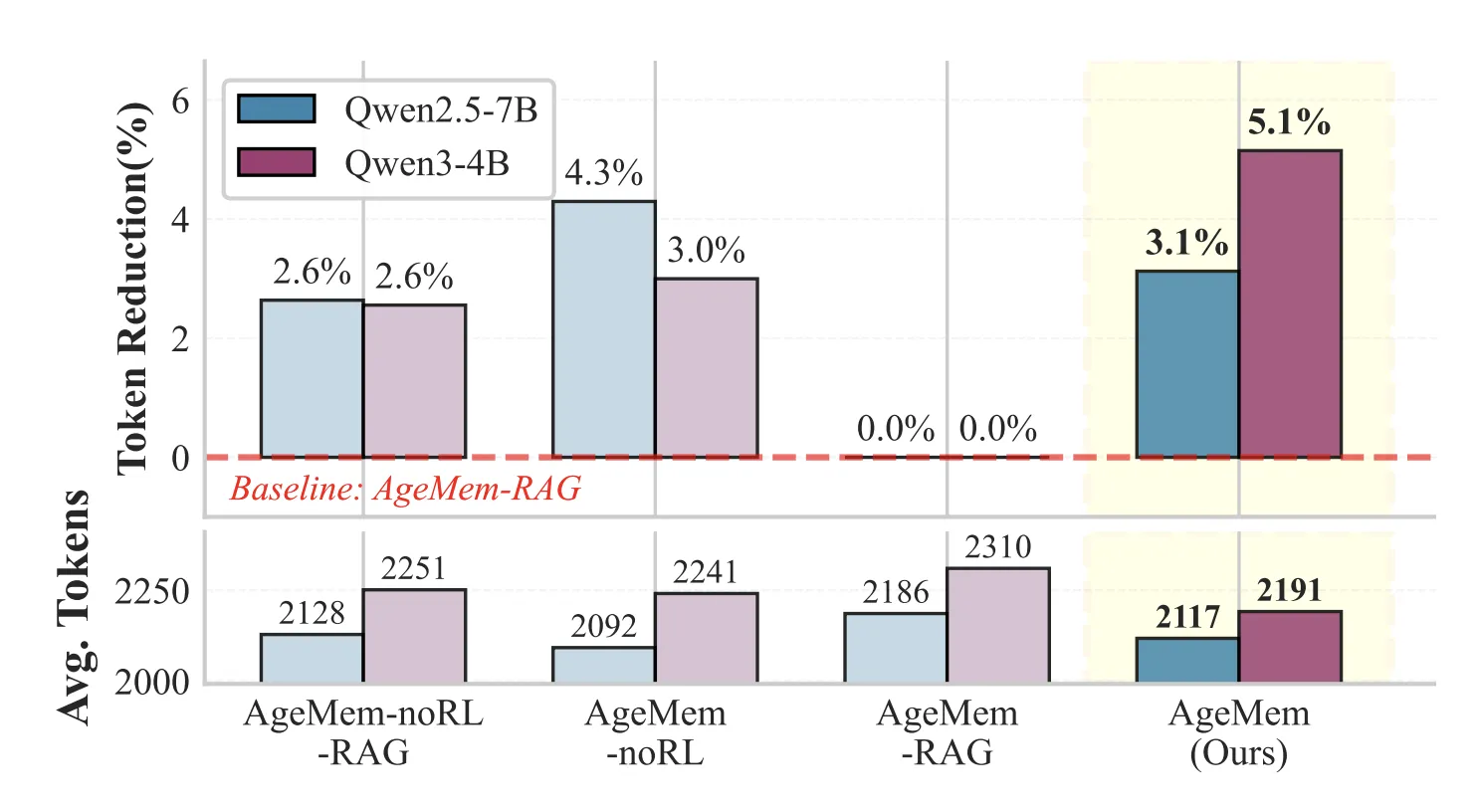
Brief time period reminiscence instruments scale back immediate size whereas preserving efficiency. On HotpotQA, configurations with STM instruments use about 3 to five p.c fewer tokens per immediate than variants that change STM instruments with a retrieval pipeline.
Ablation research affirm that every element issues. Including solely long run reminiscence instruments on prime of a no reminiscence baseline already yields clear good points. Including reinforcement studying on these instruments improves scores additional. The total system with each long run and brief time period instruments plus RL provides as much as 21.7 share factors enchancment over the no reminiscence baseline on SciWorld.
Implications for LLM agent design
AgeMem suggests a design sample for future agentic programs. Reminiscence needs to be dealt with as a part of the discovered coverage, not as two exterior subsystems. By turning storage, retrieval, summarization and filtering into express instruments and coaching them collectively with language technology, the agent learns when to recollect, when to overlook and find out how to handle context effectively throughout lengthy horizons.
Key Takeaways
- AgeMem turns reminiscence operations into express instruments, so the identical coverage that generates textual content additionally decides when to
ADD,UPDATE,DELETE,RETRIEVE,SUMMARYandFILTERreminiscence. - Long run and brief time period reminiscence are educated collectively via a 3 stage RL setup the place long run reminiscence persists throughout levels and brief time period context is reset to implement retrieval based mostly reasoning.
- The reward perform combines job accuracy, context administration high quality and long run reminiscence high quality with uniform weights, plus penalties for context overflow and extreme dialogue size.
- Throughout ALFWorld, SciWorld, BabyAI, PDDL duties and HotpotQA, AgeMem on Qwen2.5-7B and Qwen3-4B persistently outperforms reminiscence baselines akin to LangMem, A Mem and Mem0 on common scores and reminiscence high quality metrics.
- Brief time period reminiscence instruments scale back immediate size by about 3 to five p.c in comparison with RAG fashion baselines whereas preserving or bettering efficiency, displaying that discovered summarization and filtering can change handcrafted context dealing with guidelines.
Take a look at the FULL PAPER right here. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be part of us on telegram as properly.
Take a look at our newest launch of ai2025.dev, a 2025-focused analytics platform that turns mannequin launches, benchmarks, and ecosystem exercise right into a structured dataset you’ll be able to filter, evaluate, and export.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.