

{kind=link}
On the planet of Massive Language Fashions (LLMs), velocity is the one function that issues as soon as accuracy is solved. For a human, ready 1 second for a search result’s effective. For an AI agent performing 10 sequential searches to unravel a posh job, a 1-second delay per search creates a 10-second lag. This latency kills the consumer expertise.
Exa, the search engine startup previously often called Metaphor, simply launched Exa Instantaneous. It’s a search mannequin designed to offer the world’s internet information to AI brokers in beneath 200ms. For software program engineers and information scientists constructing Retrieval-Augmented Technology (RAG) pipelines, this removes the largest bottleneck in agentic workflows.
Why Latency is the Enemy of RAG
Whenever you construct a RAG utility, your system follows a loop: the consumer asks a query, your system searches the net for context, and the LLM processes that context. If the search step takes 700ms to 1000ms, the full ‘time to first token’ turns into sluggish.
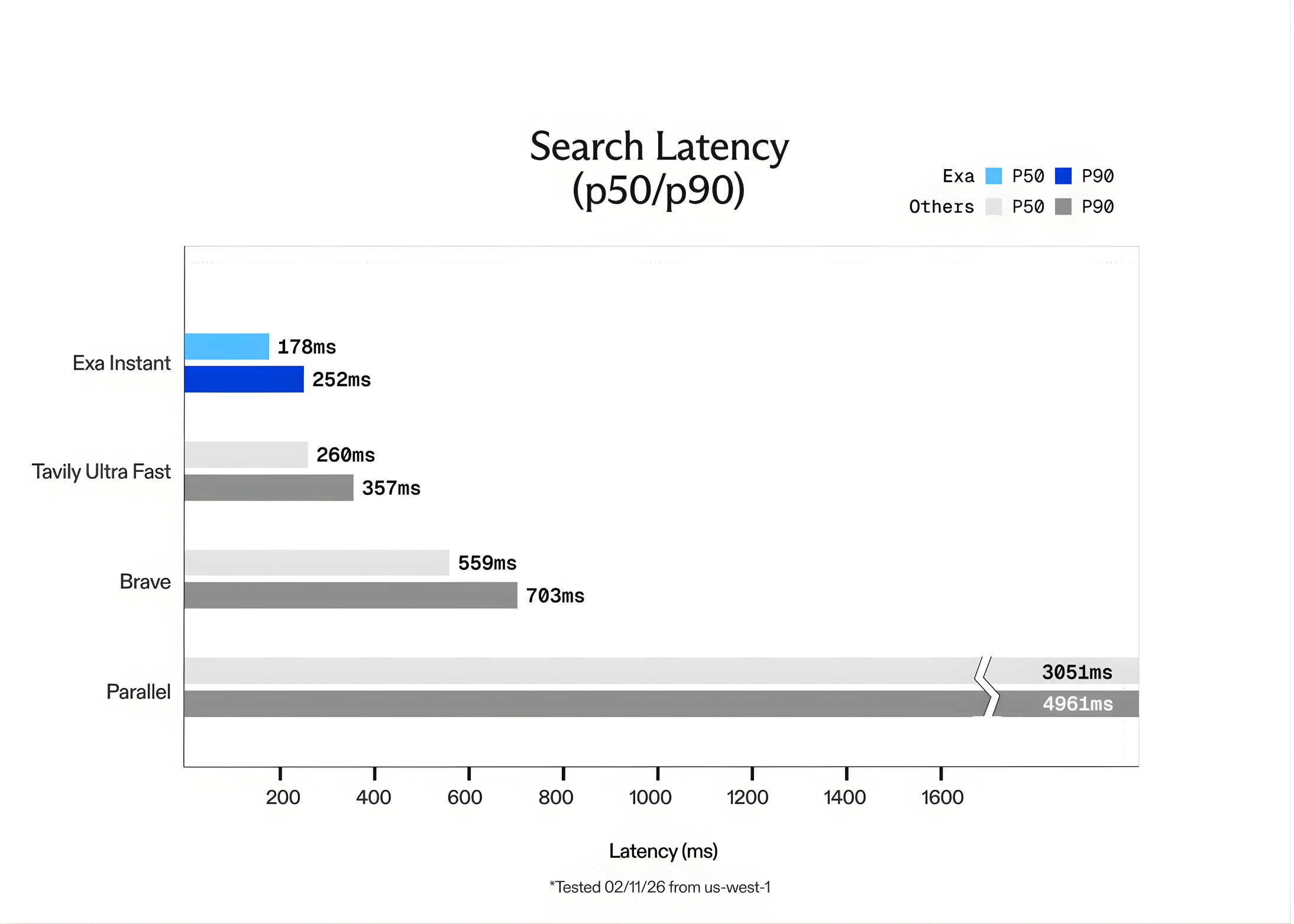
Exa Instantaneous delivers outcomes with a latency between 100ms and 200ms. In assessments performed from the us-west-1 (northern california) area, the community latency was roughly 50ms. This velocity permits brokers to carry out a number of searches in a single ‘thought’ course of with out the consumer feeling a delay.
No Extra ‘Wrapping’ Google
Most search APIs obtainable in the present day are ‘wrappers.’ They ship a question to a conventional search engine like Google or Bing, scrape the outcomes, and ship them again to you. This provides layers of overhead.
Exa Instantaneous is completely different. It’s constructed on a proprietary, end-to-end neural search and retrieval stack. As an alternative of matching key phrases, Exa makes use of embeddings and transformers to know the which means of a question. This neural method ensures the outcomes are related to the AI’s intent, not simply the particular phrases used. By proudly owning all the stack from the crawler to the inference engine, Exa can optimize for velocity in ways in which ‘wrapper’ APIs can’t.
Benchmarking the Pace
The Exa workforce benchmarked Exa Instantaneous in opposition to different common choices like Tavily Extremely Quick and Courageous. To make sure the assessments have been honest and averted ‘cached’ outcomes, the workforce used the SealQA question dataset. Additionally they added random phrases generated by GPT-5 to every question to pressure the engine to carry out a recent search each time.
The outcomes confirmed that Exa Instantaneous is as much as 15x quicker than opponents. Whereas Exa presents different fashions like Exa Quick and Exa Auto for higher-quality reasoning, Exa Instantaneous is the clear alternative for real-time purposes the place each millisecond counts.
Pricing and Developer Integration
The transition to Exa Instantaneous is straightforward. The API is accessible via the dashboard.exa.ai platform.
- Price: Exa Instantaneous is priced at $5 per 1,000 requests.
- Capability: It searches the identical huge index of the net as Exa’s extra highly effective fashions.
- Accuracy: Whereas designed for velocity, it maintains excessive relevance. For specialised entity searches, Exa’s Websets product stays the gold normal, proving to be 20x extra right than Google for complicated queries.
The API returns clear content material prepared for LLMs, eradicating the necessity for builders to put in writing customized scraping or HTML cleansing code.
Key Takeaways
- Sub-200ms Latency for Actual-Time Brokers: Exa Instantaneous is optimized for ‘agentic’ workflows the place velocity is a bottleneck. By delivering leads to beneath 200ms (and community latency as little as 50ms), it permits AI brokers to carry out multi-step reasoning and parallel searches with out the lag related to conventional search engines like google and yahoo.
- Proprietary Neural Stack vs. ‘Wrappers‘: In contrast to many search APIs that merely ‘wrap’ Google or Bing (including 700ms+ of overhead), Exa Instantaneous is constructed on a proprietary, end-to-end neural search engine. It makes use of a customized transformer-based structure to index and retrieve internet information, providing as much as 15x quicker efficiency than present options like Tavily or Courageous.
- Price-Environment friendly Scaling: The mannequin is designed to make search a ‘primitive’ somewhat than an costly luxurious. It’s priced at $5 per 1,000 requests, permitting builders to combine real-time internet lookups at each step of an agent’s thought course of with out breaking the finances.
- Semantic Intent over Key phrases: Exa Instantaneous leverages embeddings to prioritize the ‘which means’ of a question somewhat than precise phrase matches. That is notably efficient for RAG (Retrieval-Augmented Technology) purposes, the place discovering ‘link-worthy’ content material that matches an LLM’s context is extra useful than easy key phrase hits.
- Optimized for LLM Consumption: The API supplies extra than simply URLs; it presents clear, parsed HTML, Markdown, and token-efficient highlights. This reduces the necessity for customized scraping scripts and minimizes the variety of tokens the LLM must course of, additional rushing up all the pipeline.
Try the Technical particulars. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.
