

{kind=link}
Allen Institute for AI (AI2) Researchers introduce SERA, Smooth Verified Environment friendly Repository Brokers, as a coding agent household that goals to match a lot bigger closed programs utilizing solely supervised coaching and artificial trajectories.
What’s SERA?
SERA is the primary launch in AI2’s Open Coding Brokers sequence. The flagship mannequin, SERA-32B, is constructed on the Qwen 3 32B structure and is educated as a repository degree coding agent.
On SWE bench Verified at 32K context, SERA-32B reaches 49.5 p.c resolve charge. At 64K context it reaches 54.2 p.c. These numbers place it in the identical efficiency band as open weight programs corresponding to Devstral-Small-2 with 24B parameters and GLM-4.5 Air with 110B parameters, whereas SERA stays totally open in code, knowledge, and weights.
The sequence consists of 4 fashions right this moment, SERA-8B, SERA-8B GA, SERA-32B, and SERA-32B GA. All are launched on Hugging Face underneath an Apache 2.0 license.
Smooth Verified Era
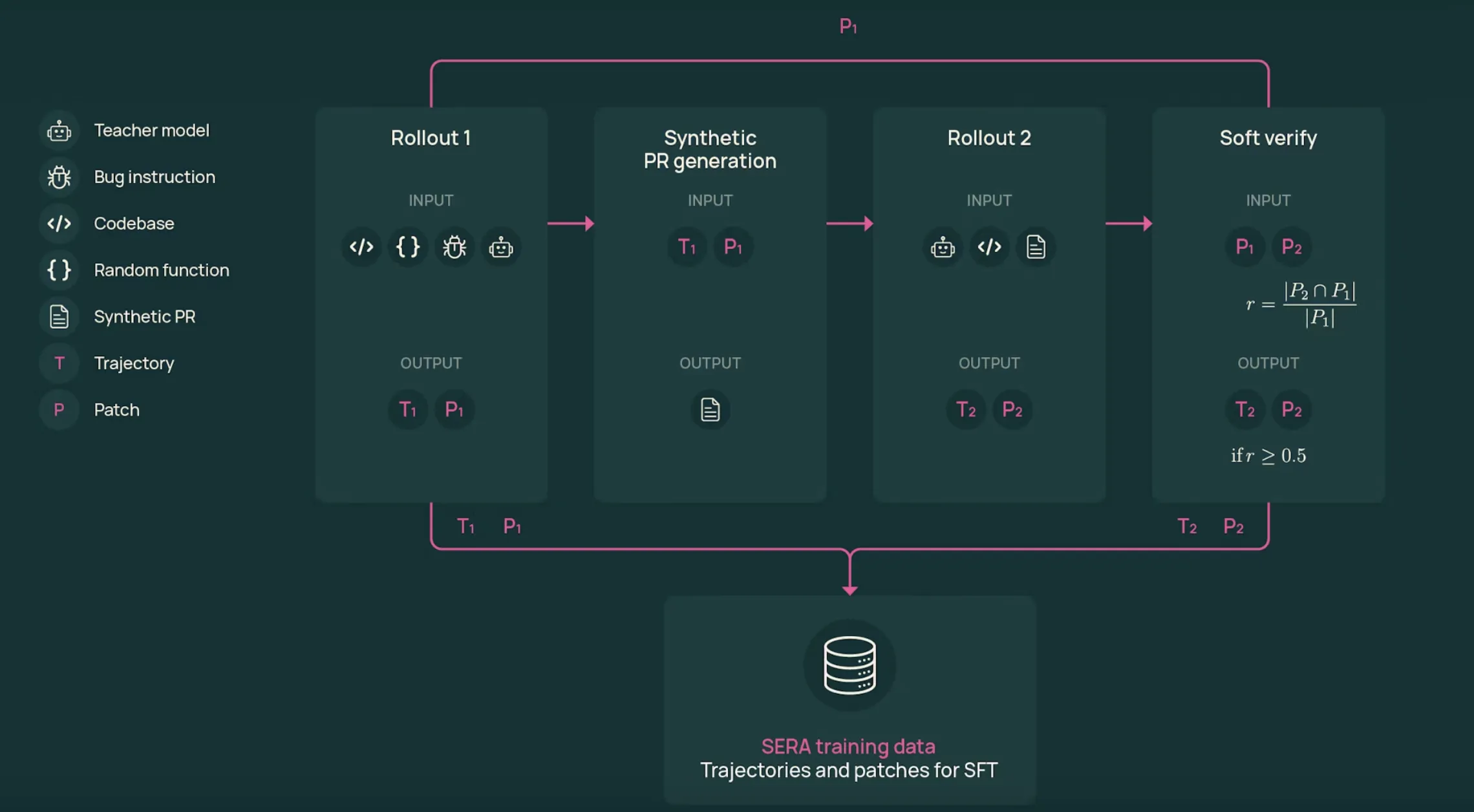
The coaching pipeline depends on Smooth Verified Era, SVG. SVG produces agent trajectories that seem like practical developer workflows, then makes use of patch settlement between two rollouts as a smooth sign of correctness.
The method is:
- First rollout: A perform is sampled from an actual repository. The instructor mannequin, GLM-4.6 within the SERA-32B setup, receives a bug fashion or change description and operates with instruments to view recordsdata, edit code, and run instructions. It produces a trajectory T1 and a patch P1.
- Artificial pull request: The system converts the trajectory right into a pull request like description. This textual content summarizes intent and key edits in a format just like actual pull requests.
- Second rollout: The instructor begins once more from the unique repository, however now it solely sees the pull request description and the instruments. It produces a brand new trajectory T2 and patch P2 that tries to implement the described change.
- Smooth verification: The patches P1 and P2 are in contrast line by line. A recall rating r is computed because the fraction of modified traces in P1 that seem in P2. When r equals 1 the trajectory is difficult verified. For intermediate values, the pattern is smooth verified.
The important thing consequence from the ablation examine is that strict verification isn’t required. When fashions are educated on T2 trajectories with totally different thresholds on r, even r equals 0, efficiency on SWE bench Verified is comparable at a set pattern rely. This implies that practical multi step traces, even when noisy, are invaluable supervision for coding brokers.
Knowledge scale, coaching, and value
SVG is utilized to 121 Python repositories derived from the SWE-smith corpus. Throughout GLM-4.5 Air and GLM-4.6 instructor runs, the total SERA datasets comprise greater than 200,000 trajectories from each rollouts, making this one of many largest open coding agent datasets.
SERA-32B is educated on a subset of 25,000 T2 trajectories from the Sera-4.6-Lite T2 dataset. Coaching makes use of customary supervised nice tuning with Axolotl on Qwen-3-32B for 3 epochs, studying charge 1e-5, weight decay 0.01, and most sequence size 32,768 tokens.
Many trajectories are longer than the context restrict. The analysis crew outline a truncation ratio, the fraction of steps that match into 32K tokens. They then desire trajectories that already match, and for the remaining they choose slices with excessive truncation ratio. This ordered truncation technique clearly outperforms random truncation once they examine SWE bench Verified scores.
The reported compute funds for SERA-32B, together with knowledge era and coaching, is about 40 GPU days. Utilizing a scaling legislation over dataset dimension and efficiency, the analysis crew estimated that the SVG strategy is round 26 occasions cheaper than reinforcement studying primarily based programs corresponding to SkyRL-Agent and 57 occasions cheaper than earlier artificial knowledge pipelines corresponding to SWE-smith for reaching comparable SWE-bench scores.

Repository specialization
A central use case is adapting an agent to a selected repository. The analysis crew research this on three main SWE-bench Verified tasks, Django, SymPy, and Sphinx.
For every repository, SVG generates on the order of 46,000 to 54,000 trajectories. Attributable to compute limits, the specialization experiments prepare on 8,000 trajectories per repository, mixing 3,000 smooth verified T2 trajectories with 5,000 filtered T1 trajectories.
At 32K context, these specialised college students match or barely outperform the GLM-4.5-Air instructor, and in addition examine nicely with Devstral-Small-2 on these repository subsets. For Django, a specialised scholar reaches 52.23 p.c resolve charge versus 51.20 p.c for GLM-4.5-Air. For SymPy, the specialised mannequin reaches 51.11 p.c versus 48.89 p.c for GLM-4.5-Air.
Key Takeaways
- SERA turns coding brokers right into a supervised studying downside: SERA-32B is educated with customary supervised nice tuning on artificial trajectories from GLM-4.6, with no reinforcement studying loop and no dependency on repository take a look at suites.
- Smooth Verified Era removes the necessity for checks: SVG makes use of two rollouts and patch overlap between P1 and P2 to compute a smooth verification rating, and the analysis crew present that even unverified or weakly verified trajectories can prepare efficient coding brokers.
- Giant, practical agent dataset from actual repositories: The pipeline applies SVG to 121 Python tasks from the SWE smith corpus, producing greater than 200,000 trajectories and creating one of many largest open datasets for coding brokers.
- Environment friendly coaching with specific price and scaling evaluation: SERA-32B trains on 25,000 T2 trajectories and the scaling examine reveals that SVG is about 26 occasions cheaper than SkyRL-Agent and 57 occasions cheaper than SWE-smith at comparable SWE bench Verified efficiency.
Try the Paper, Repo and Mannequin Weights. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.