

{kind=link}
Do curated, tool-grounded demonstrations construct stronger software program brokers than broad piles of generic instruction information? A crew of researchers from Shanghai Jiao Tong College and SII Generative AI Analysis Lab (GAIR) proposes LIMI (“Much less Is Extra for Company”), a supervised fine-tuning technique that turns a base mannequin right into a succesful software program/analysis agent utilizing 78 samples. LIMI scores 73.5% common on AgencyBench (FTFC 71.7, RC@3 74.2, SR@3 74.6), beating sturdy baselines (GLM-4.5 45.1, Qwen3-235B-A22B 27.5, Kimi-K2 24.1, DeepSeek-V3.1 11.9) and even surpassing variants educated on 10,000 samples—with 128× much less information.

What precisely is new?
- Company Effectivity Precept: LIMI state that agentic competence scales extra with information high quality/construction than uncooked pattern rely. The analysis crew fine-tune GLM-4.5/GLM-4.5-Air on 78 long-horizon, tool-use trajectories (samples) and report massive features on AgencyBench and generalization suites (TAU2-bench, EvalPlus-HE/MBPP, DS-1000, SciCode).
- Minimal however dense supervision. Every trajectory (~13k–152k tokens; ~42.4k avg.) captures full multi-turn workflows—mannequin reasoning, instrument calls, and setting observations—collected within the SII-CLI execution setting. Duties span “vibe coding” (interactive software program improvement) and analysis workflows (search, evaluation, experiment design).
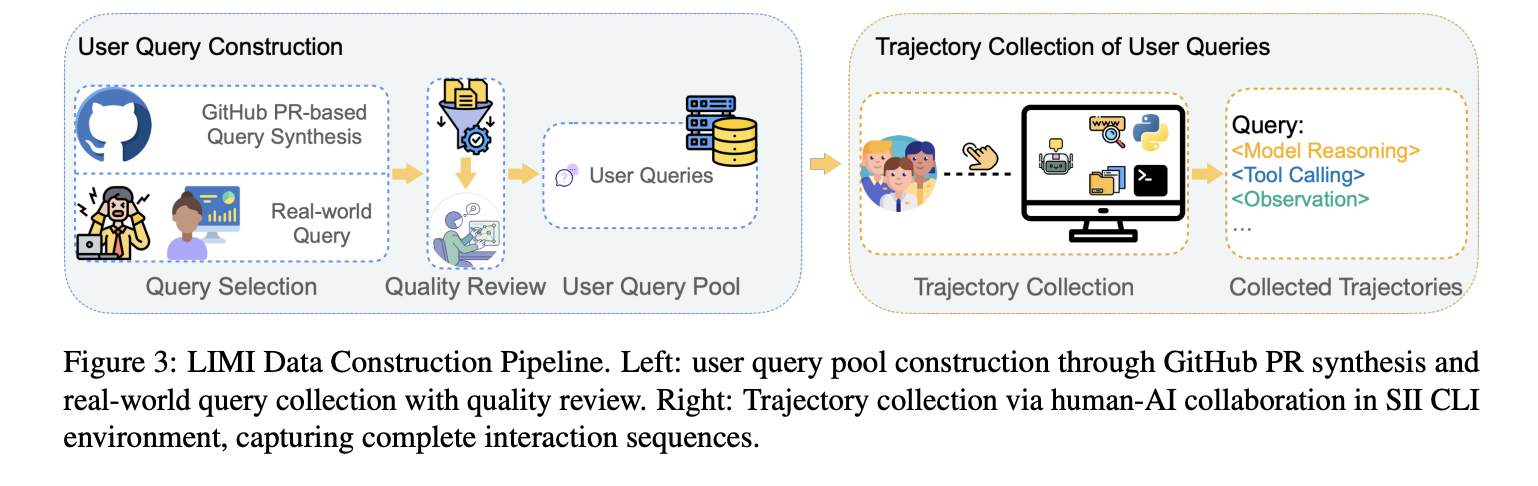
How does it work?
- Base fashions: GLM-4.5 (355B) and GLM-4.5-Air (106B). Coaching makes use of the slime SFT framework with an identical configs throughout comparisons (to isolate information results).
- Knowledge development: 60 actual queries from practitioners + 18 synthesized from high-star GitHub PRs (tight QA by PhD annotators). For every question, LIMI logs the total agent trajectory to profitable completion inside SII-CLI.
- Analysis: AgencyBench (R=3 rounds) with FTFC, SR@3, RC@3; plus generalization suites (TAU2-airline/retail Go^4, EvalPlus HE/MBPP, DS-1000, SciCode).
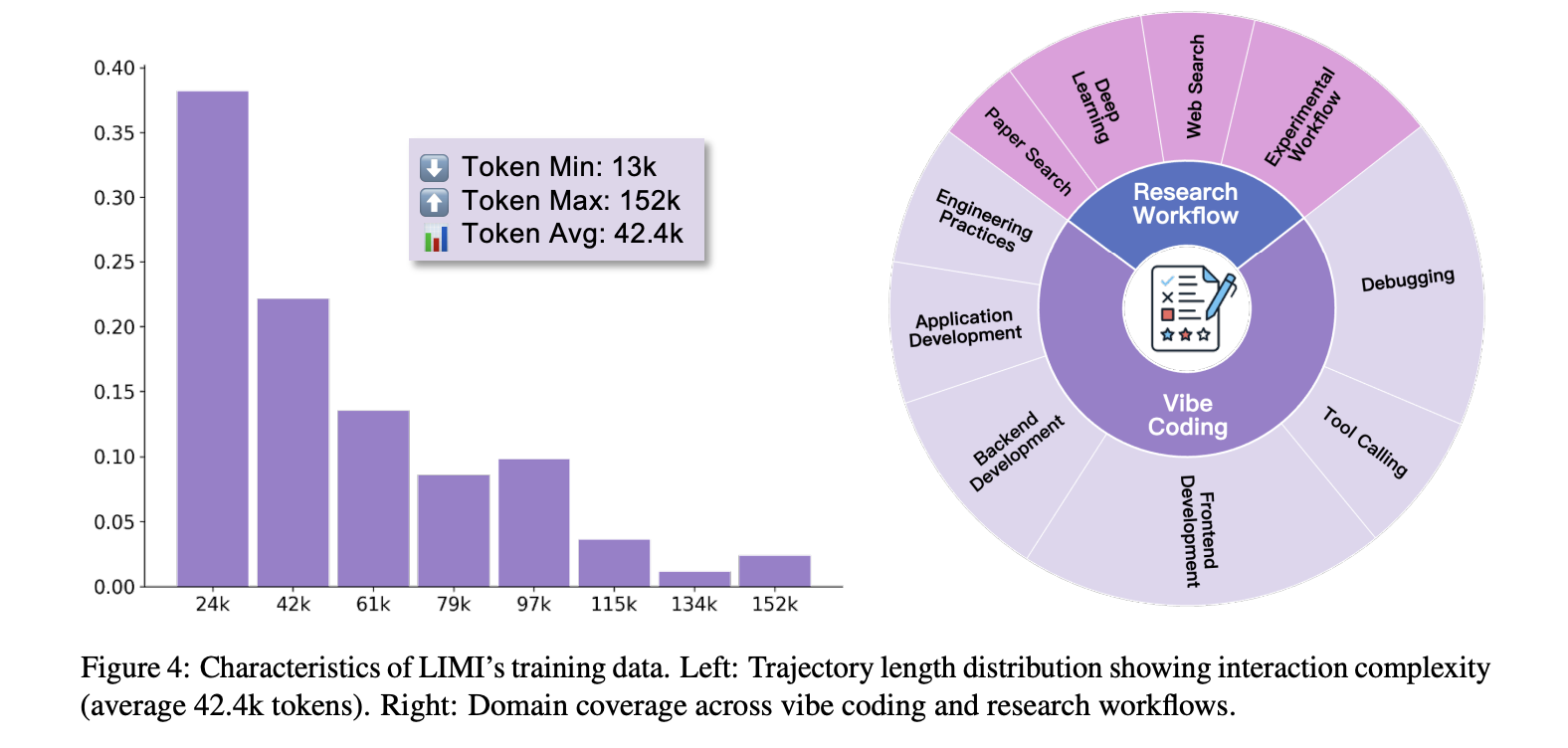
Outcomes
- AgencyBench (avg): 73.5%. LIMI vs. GLM-4.5 (+28.4 pts); FTFC 71.7% vs 37.8%; SR@3 74.6% vs 47.4%.
- Knowledge effectivity: LIMI (78 samples) outperforms GLM-4.5 educated on AFM-CodeAgent SFT (10,000 samples): 73.5% vs 47.8%—+53.7% absolute with 128× much less information. Comparable gaps maintain vs AFM-WebAgent (7,610) and CC-Bench-Traj (260).
- Generalization: Throughout tool-use/coding/scientific computing, LIMI averages ~57%, exceeding GLM-4.5 and different baselines; with out instrument entry, LIMI nonetheless leads barely (50.0% vs 48.7% for GLM-4.5), indicating intrinsic features past setting tooling.
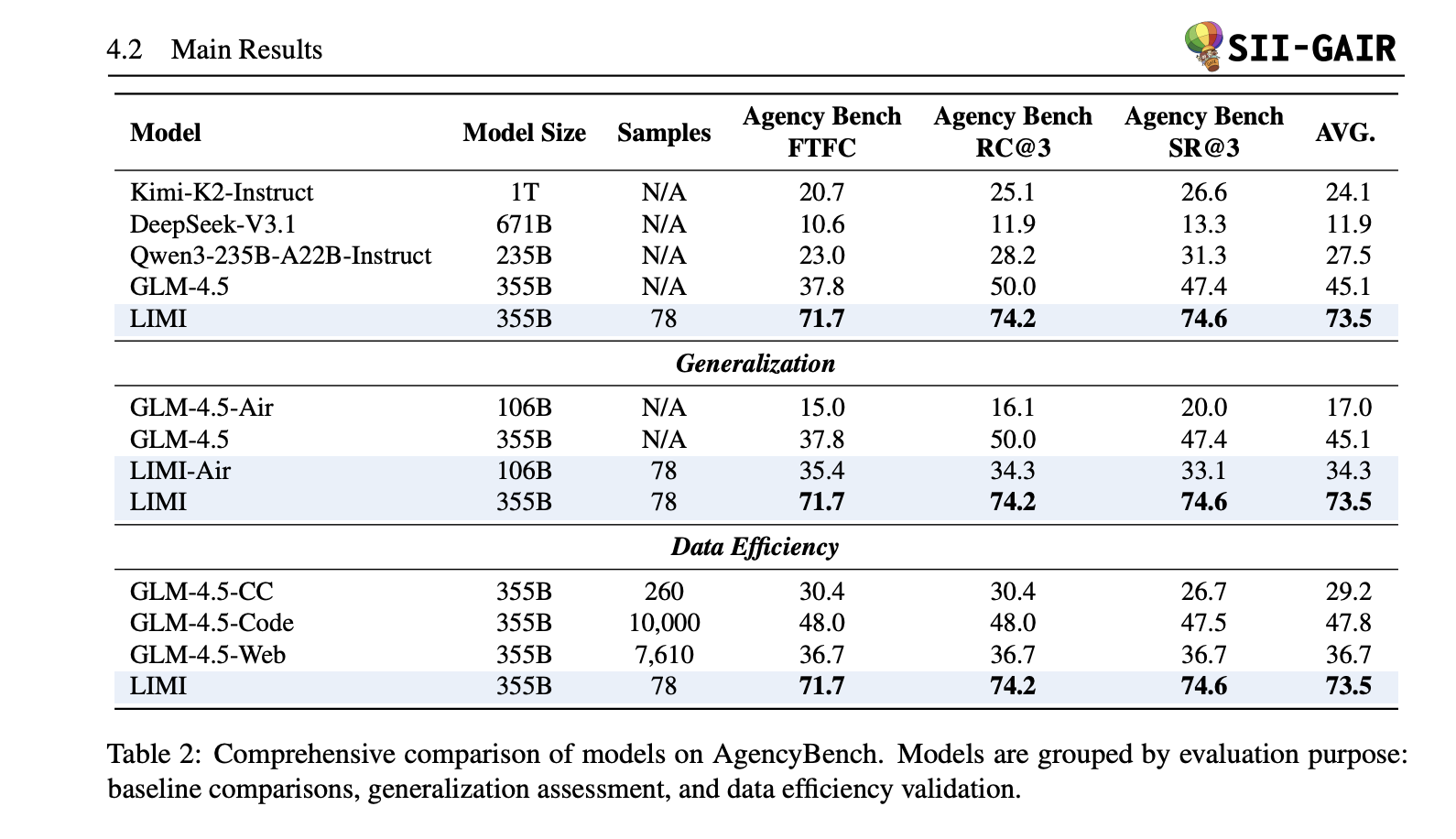
Key Takeaways
- Knowledge effectivity dominates scale. LIMI reaches 73.5% common on AgencyBench utilizing curated trajectories, surpassing GLM-4.5 (45.1%) and displaying a +53.7-point benefit over a 10k-sample SFT baseline—with 128× fewer samples.
- Trajectory high quality, not bulk. Coaching information are long-horizon, tool-grounded workflows in collaborative software program improvement and scientific analysis, collected through the SII-CLI execution stack referenced by the paper.
- Throughout-metric features. On AgencyBench, LIMI experiences FTFC 71.7%, SR@3 74.6%, and powerful RC@3, with detailed tables displaying massive margins over baselines; generalization suites (TAU2, EvalPlus-HE/MBPP, DS-1000, SciCode) common 57.2%.
- Works throughout scales. Tremendous-tuning GLM-4.5 (355B) and GLM-4.5-Air (106B) each yields massive deltas over their bases, indicating technique robustness to mannequin dimension.
The analysis crew trains GLM-4.5 variants with 78 curated, long-horizon, tool-grounded trajectories captured in a CLI setting spanning software-engineering and analysis duties. It experiences 73.5% common on AgencyBench with FTFC, RC@3, and SR@3 metrics; baseline GLM-4.5 is reported at 45.1%. A comparability towards a ten,000-sample AFM-CodeAgent SFT baseline reveals 73.5% vs 47.8%; tool-free analysis signifies intrinsic features (≈50.0% for LIMI vs 48.7% GLM-4.5). Trajectories are multi-turn and token-dense, emphasizing planning, instrument orchestration, and verification.
Take a look at the Paper, GitHub Web page and Mannequin Card on HF. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.