

{kind=link}
Most builders deal with prompting as an afterthought—write one thing affordable, observe the output, and iterate if wanted. That strategy works till reliability turns into essential. As LLMs transfer into manufacturing programs, the distinction between a immediate that often works and one which works persistently turns into an engineering concern. In response, the analysis group has formalized prompting right into a set of well-defined methods, every designed to deal with particular failure modes—whether or not in construction, reasoning, or fashion. These strategies function fully on the immediate layer, requiring no fine-tuning, mannequin adjustments, or infrastructure upgrades.
This text focuses on 5 such methods: role-specific prompting, unfavourable prompting, JSON prompting, Attentive Reasoning Queries (ARQ), and verbalized sampling. Somewhat than protecting acquainted baselines like zero-shot or fundamental chain-of-thought, the emphasis right here is on what adjustments when these methods are utilized. Every is demonstrated via side-by-side comparisons on the identical activity, highlighting the influence on output high quality and explaining the underlying mechanism.
Right here, we’re establishing a minimal surroundings to work together with the OpenAI API. We securely load the API key at runtime utilizing getpass, initialize the consumer, and outline a light-weight chat wrapper to ship system and consumer prompts to the mannequin (gpt-4o-mini). This retains our experimentation loop clear and reusable whereas focusing solely on immediate variations.

The helper capabilities (part and divider) are only for formatting outputs, making it simpler to check baseline vs. improved prompts facet by facet. In case you don’t have already got an API key, you possibly can create one from the official dashboard right here: https://platform.openai.com/api-keys
import json
from openai import OpenAI
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')
consumer = OpenAI()
MODEL = "gpt-4o-mini"
def chat(system: str, consumer: str, **kwargs) -> str:
"""Minimal wrapper across the chat completions endpoint."""
response = consumer.chat.completions.create(
mannequin=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
**kwargs,
)
return response.decisions[0].message.content material
def part(title: str) -> None:
print()
print("=" * 60)
print(f" {title}")
print("=" * 60)
def divider(label: str) -> None:
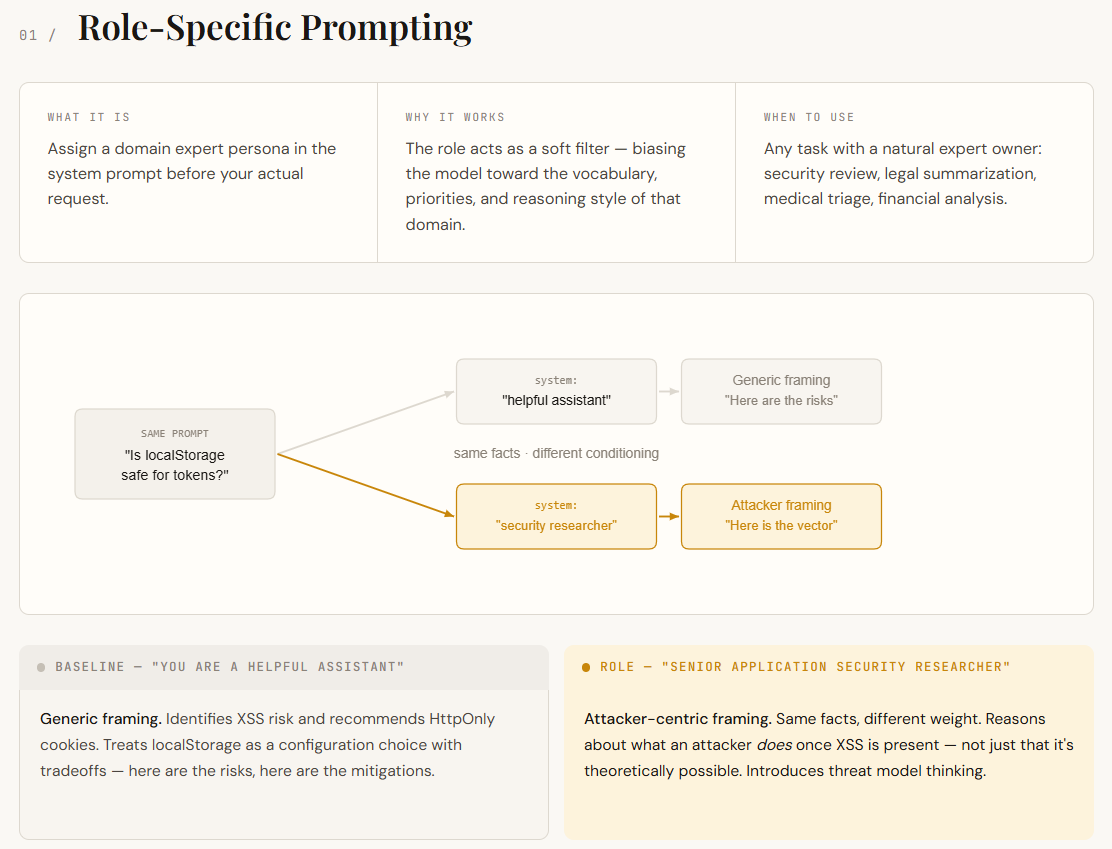
print(f"n── {label} {'─' * (54 - len(label))}")Language fashions are educated on a large mixture of domains—safety, advertising and marketing, authorized, engineering, and extra. If you don’t specify a job, the mannequin pulls from all of them, which results in solutions which can be usually appropriate however considerably generic. Function-specific prompting fixes this by assigning a persona within the system immediate (e.g., “You’re a senior software safety researcher”). This acts like a filter, pushing the mannequin to reply utilizing the language, priorities, and reasoning fashion of that area.
On this instance, each responses establish the XSS danger and suggest HttpOnly cookies — the underlying info are similar. The distinction is in how the mannequin frames the issue. The baseline treats localStorage as a configuration alternative with tradeoffs. The role-specific response treats it as an assault floor: it causes about what an attacker can do as soon as XSS is current, not simply that XSS is theoretically attainable. That shift in framing — from “listed here are the dangers” to “here’s what an attacker does with these dangers” — is the conditioning impact in motion. No new info was offered. The immediate simply modified which a part of the mannequin’s information bought weighted.
part("TECHNIQUE 1 -- Function-Particular Prompting")
QUESTION = "Our internet app shops session tokens in localStorage. Is that this an issue?"
baseline_1 = chat(
system="You're a useful assistant.",
consumer=QUESTION,
)
role_specific = chat(
system=(
"You're a senior software safety researcher specializing in "
"internet authentication vulnerabilities. You suppose when it comes to assault "
"floor, menace fashions, and OWASP tips."
),
consumer=QUESTION,
)
divider("Baseline")
print(baseline_1)
divider("Function-specific (safety researcher)")
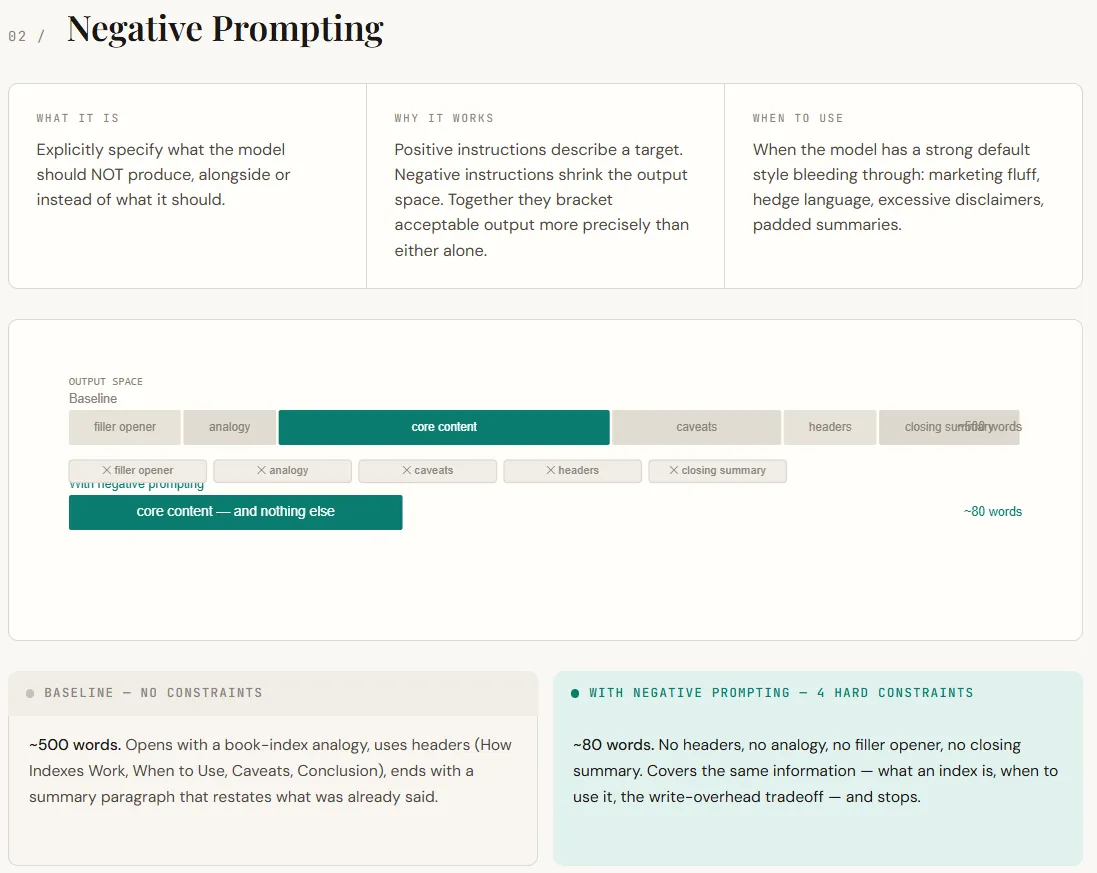
print(role_specific)Adverse prompting focuses on telling the mannequin what to not do. By default, LLMs comply with patterns realized throughout coaching and RLHF—they add pleasant openings, analogies, hedging (“it relies upon”), and shutting summaries. Whereas this makes responses really feel useful, it usually provides pointless noise in technical contexts. Adverse prompting works by eradicating these defaults. As an alternative of simply describing the specified output, you additionally prohibit undesirable behaviors, which narrows the mannequin’s output area and results in extra exact responses.
Within the output, the distinction is straight away seen. The baseline response stretches into an extended, structured rationalization with analogies, headers, and a redundant conclusion. The negatively prompted model delivers the identical core info in a a lot shorter kind—direct, concise, and with out filler. Nothing important is misplaced; the immediate merely removes the mannequin’s tendency to over-explain and pad the response.
part("TECHNIQUE 2 -- Adverse Prompting")
TOPIC = "Clarify what a database index is and whenever you'd use one."
baseline_2 = chat(
system="You're a useful assistant.",
consumer=TOPIC,
)
unfavourable = chat(
system=(
"You're a senior backend engineer writing inner documentation.n"
"Guidelines:n"
"- Do NOT use advertising and marketing language or filler phrases like 'nice query' or 'actually'.n"
"- Do NOT embody caveats like 'it relies upon' with out instantly resolving them.n"
"- Do NOT use analogies until they're mandatory. In case you use one, hold it to at least one sentence.n"
"- Do NOT pad the response -- for those who've made the purpose, cease.n"
),
consumer=TOPIC,
)
divider("Baseline")
print(baseline_2)
divider("With unfavourable prompting")
print(unfavourable)JSON prompting turns into vital when LLM outputs should be consumed by code quite than simply learn by people. Free-form responses are inconsistent—construction varies, key particulars are embedded in paragraphs, and small wording adjustments break parsing logic. By defining a JSON schema within the immediate, you flip construction into a tough constraint. This not solely standardizes the output format but additionally forces the mannequin to arrange its reasoning into clearly outlined fields like professionals, cons, sentiment, and ranking.
Within the output, the distinction is evident. The baseline response is readable however unstructured—professionals, cons, and sentiment are combined into narrative textual content, making it tough to parse. The JSON-prompted model, nevertheless, returns clear, well-defined fields that may be instantly loaded and utilized in code with none post-processing. Data that was beforehand implied is now express and separated, making the output straightforward to retailer, question, and evaluate at scale.

part("TECHNIQUE 3 -- JSON Prompting")
REVIEW = """
Actually combined emotions about this laptop computer. The show is beautiful -- simply the most effective I've
seen at this worth vary -- and the keyboard is surprisingly snug for lengthy periods.
Battery life, alternatively, barely will get me via a 6-hour workday, which is
disappointing. Fan noise beneath load can be fairly aggressive. For mild work it is nice,
however I would not suggest it for anybody who must run heavy software program.
"""
SCHEMA = """
unfavourable
"""
baseline_3 = chat(
system="You're a useful assistant.",
consumer=f"Summarize this product evaluation:nn{REVIEW}",
)
json_output = chat(
system=(
"You're a product evaluation parser. Extract structured info from critiques.n"
"You MUST return solely a legitimate JSON object. No preamble, no rationalization, no markdown fences.n"
f"The JSON should match this schema precisely:n{SCHEMA}"
),
consumer=f"Parse this evaluation:nn{REVIEW}",
)
divider("Baseline (free-form)")
print(baseline_3)
divider("JSON prompting (uncooked output)")
print(json_output)
divider("Parsed & usable in code")
parsed = json.hundreds(json_output)
print(f"Sentiment : {parsed['overall_sentiment']}")
print(f"Ranking : {parsed['rating']}/5")
print(f"Professionals : {', '.be a part of(parsed['pros'])}")
print(f"Cons : {', '.be a part of(parsed['cons'])}")
print(f"Beneficial for : {parsed['recommended_for']}")
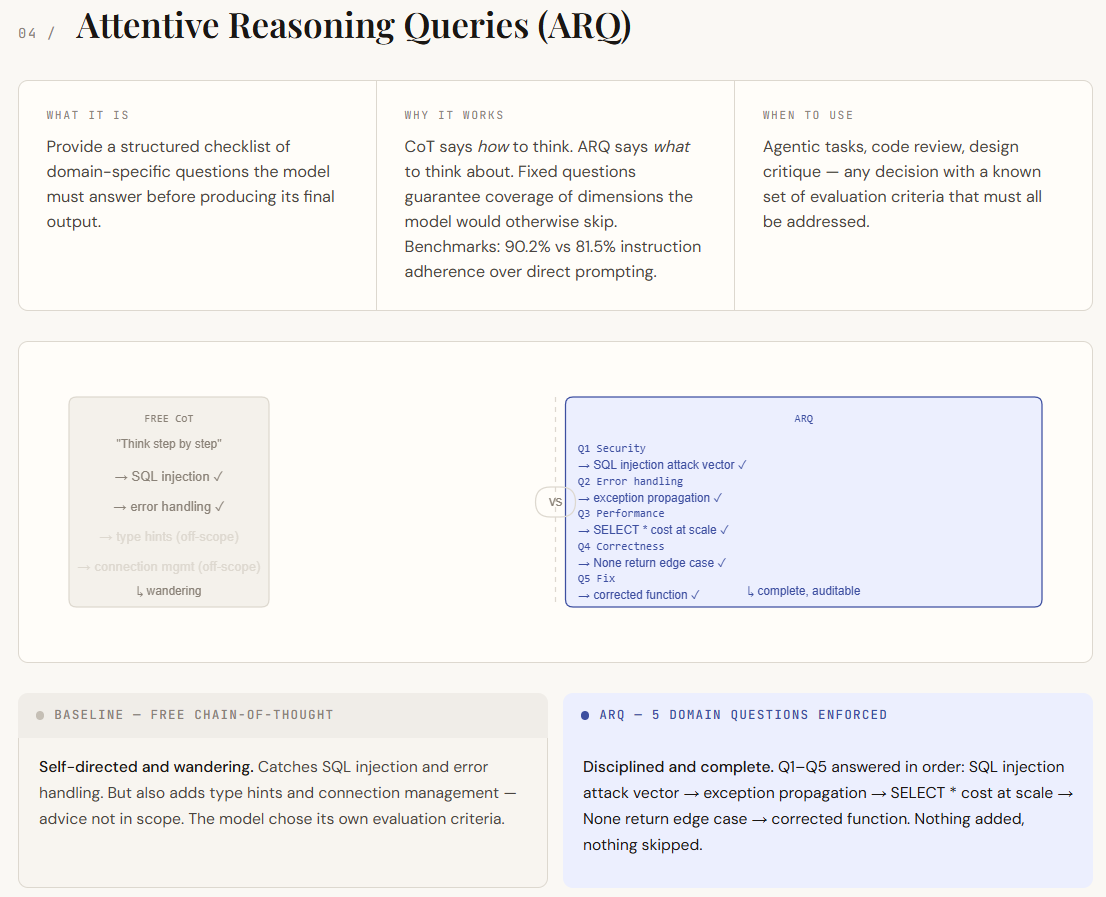
print(f"Keep away from if : {parsed['not_recommended_for']}")Attentive Reasoning Queries (ARQ) construct on chain-of-thought prompting however take away its largest weak point—unstructured reasoning. In commonplace CoT, the mannequin decides what to give attention to, which might result in gaps or irrelevant particulars. ARQ replaces this with a set set of domain-specific questions that the mannequin should reply so as. This ensures that each one essential facets are coated, shifting management from the mannequin to the immediate designer. As an alternative of simply guiding how the mannequin thinks, ARQ defines what it should take into consideration.
Within the output, the distinction exhibits up as self-discipline and protection. The baseline CoT response identifies key points however drifts into much less related areas and misses deeper evaluation in locations. The ARQ model, nevertheless, systematically addresses every required level—clearly isolating vulnerabilities, dealing with edge instances, and evaluating efficiency implications. Every query acts as a checkpoint, making the response extra structured, full, and simpler to audit.
part("TECHNIQUE 4 -- Attentive Reasoning Queries (ARQ)")
CODE_TO_REVIEW = """
def get_user(user_id):
question = f"SELECT * FROM customers WHERE id = {user_id}"
end result = db.execute(question)
return end result[0] if end result else None
"""
ARQ_QUESTIONS = """
Earlier than giving your ultimate evaluation, reply every of the next questions so as:
Q1 [Security]: Does this code have any injection vulnerabilities?
If sure, describe the precise assault vector.
Q2 [Error handling]: What occurs if db.execute() throws an exception?
Is that acceptable?
Q3 [Performance]: Does this question retrieve extra knowledge than mandatory?
What's the value at scale?
This fall [Correctness]: Are there edge instances within the return logic that might
trigger a silent bug downstream?
Q5 [Fix]: Write a corrected model of the operate that addresses
all points discovered above.
"""
baseline_cot = chat(
system="You're a senior software program engineer. Assume step-by-step.",
consumer=f"Assessment this Python operate:nn{CODE_TO_REVIEW}",
)
arq_result = chat(
system="You're a senior software program engineer conducting a security-aware code evaluation.",
consumer=f"Assessment this Python operate:nn{CODE_TO_REVIEW}nn{ARQ_QUESTIONS}",
)
divider("Baseline (free CoT)")
print(baseline_cot)
divider("ARQ (structured reasoning guidelines)")
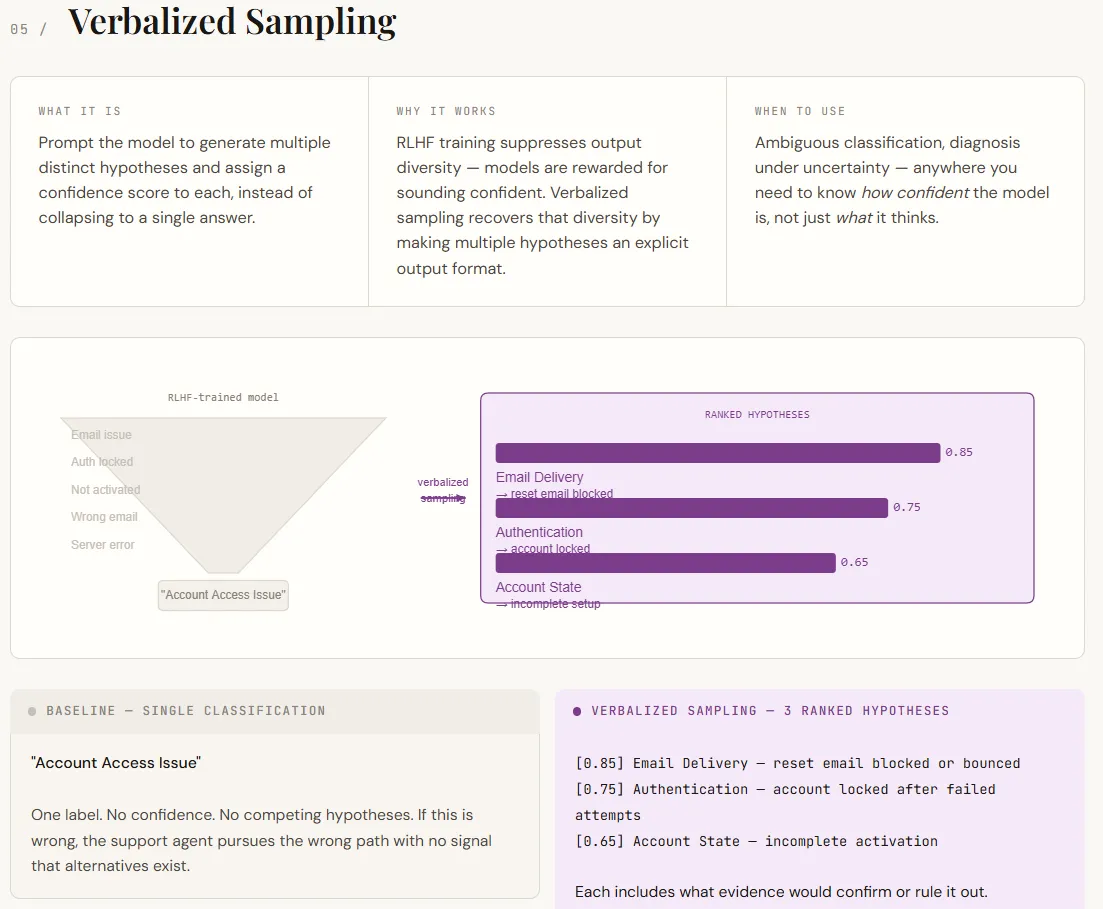
print(arq_result)Verbalized sampling addresses a key limitation of LLMs: they have a tendency to return a single, assured reply even when a number of interpretations are attainable. This occurs as a result of alignment coaching favors decisive outputs. Because of this, the mannequin hides its inner uncertainty. Verbalized sampling fixes this by explicitly asking for a number of hypotheses, together with confidence rankings and supporting proof. As an alternative of forcing one reply, it surfaces a spread of believable outcomes—all inside the immediate, with no need mannequin adjustments.
Within the output, this shifts the end result from a single label to a structured diagnostic view. The baseline offers one classification with no indication of uncertainty. The verbalized model, nevertheless, lists a number of ranked hypotheses, every with a proof and a method to validate or reject it. This makes the output extra actionable, turning it right into a decision-making assist quite than simply a solution. The boldness scores themselves aren’t exact possibilities, however they successfully point out relative probability, which is commonly enough for prioritization and downstream workflows.
part("TECHNIQUE 5 -- Verbalized Sampling")
SUPPORT_TICKET = """
Hello, I arrange my account final week however I can not log in anymore. I attempted resetting
my password however the e-mail by no means arrives. I additionally tried a unique browser. Nothing works.
"""
baseline_5 = chat(
system="You're a assist ticket classifier. Classify the difficulty.",
consumer=f"Ticket:n{SUPPORT_TICKET}",
)
verbalized = chat(
system=(
"You're a assist ticket classifier.n"
"For every ticket, generate 3 distinct hypotheses concerning the root trigger. "
"For every speculation:n"
" - State the class (Authentication, Electronic mail Supply, Account State, Browser/Shopper, Different)n"
" - Describe the precise failure moden"
" - Assign a confidence rating from 0.0 to 1.0n"
" - State what further info would affirm or rule it outnn"
"Order hypotheses by confidence (highest first). "
"Then present a advisable first motion for the assist agent."
),
consumer=f"Ticket:n{SUPPORT_TICKET}",
)
divider("Baseline (single reply)")
print(baseline_5)
divider("Verbalized sampling (a number of hypotheses + confidence)")
print(verbalized)Try the Full Codes with Pocket book right here. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 130k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be a part of us on telegram as effectively.
Must companion with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Knowledge Science, particularly Neural Networks and their software in numerous areas.