

{kind=link}
Xiaomi MiMo staff publicly launched two new fashions: MiMo-V2.5-Professional and MiMo-V2.5. The benchmarks, mixed with some genuinely putting real-world activity demos, make a compelling case that open agentic AI is catching as much as the frontier quicker than most anticipated. Each fashions can be found instantly by way of API, and priced competitively.
What’s an Agentic Mannequin, and Why Does It Matter?
Most LLM benchmarks check a mannequin’s skill to reply a single, self-contained query. Agentic benchmarks check one thing a lot tougher — whether or not a mannequin can full a multi-step objective autonomously, utilizing instruments (net search, code execution, file I/O, API calls) over many turns, with out dropping monitor of the unique goal.
Consider it because the distinction between a mannequin that may reply “how do I write a lexer?” versus one that may really write a whole compiler, run exams towards it, catch regressions, and repair them — all with out a human within the loop. The latter is strictly what Xiaomi MiMo staff is demonstrating right here.
MiMo-V2.5-Professional: The Flagship
MiMo-V2.5-Professional is Xiaomi’s most succesful mannequin so far, delivering important enhancements over its predecessor, MiMo-V2-Professional, basically agentic capabilities, complicated software program engineering, and long-horizon duties.
The important thing benchmark numbers are aggressive with high closed-source fashions: SWE-bench Professional 57.2, Claw-Eval 63.8, and τ3-Bench 72.9 — putting it alongside Claude Opus 4.6 and GPT-5.4 throughout most evaluations. V2.5-Professional can maintain complicated, long-horizon duties spanning greater than a thousand device calls, demonstrating substantial enhancements in instruction following inside agentic situations, reliably adhering to refined necessities embedded in context and sustaining sturdy coherence throughout ultra-long contexts.
One behavioral property that distinguishes V2.5-Professional from earlier fashions is what Xiaomi MiMo staff calls “harness consciousness”: it makes full use of the affordances of its harness surroundings, manages its reminiscence, and shapes how its personal context is populated towards the ultimate goal. This implies the mannequin doesn’t simply execute directions mechanically. It actively optimizes its personal working surroundings to remain on monitor throughout very lengthy duties.
The three real-world activity demos Xiaomi printed illustrate precisely what “long-horizon agentic functionality” means in apply.
Demo 1 — SysY Compiler in Rust: Referred from Peking College’s Compiler Rules course challenge, this activity asks the mannequin to implement a whole SysY compiler in Rust from scratch: lexer, parser, AST, Koopa IR codegen, RISC-V meeting backend, and efficiency optimization. The reference challenge sometimes takes a PKU CS main scholar a number of weeks. MiMo-V2.5-Professional completed in 4.3 hours throughout 672 device calls, scoring an ideal 233/233 towards the course’s hidden check suite.
What’s notable isn’t simply the ultimate rating — it’s the structure of execution. Slightly than thrashing via trial and error, the mannequin constructed the compiler layer by layer: scaffold the total pipeline first, excellent Koopa IR (110/110), then the RISC-V backend (103/103), then efficiency (20/20). The primary compile alone handed 137/233 exams, a 59% chilly begin that means the structure was designed accurately earlier than a single check was run. When a refactoring step later brought about regressions, the mannequin recognized the failures, recovered, and pushed on. That is structured, self-correcting engineering habits — not pattern-matched code era.
Demo 2 — Full-Featured Desktop Video Editor: With just some easy prompts, MiMo-V2.5-Professional delivered a working desktop app: multi-track timeline, clip trimming, cross-fades, audio mixing, and export pipeline. The ultimate construct is 8,192 traces of code, produced over 1,868 device calls throughout 11.5 hours of autonomous work.
Demo 3 — Analog EDA- FVF-LDO Design: That is essentially the most technically specialised demo: a graduate-level analog-circuit EDA activity requiring the design and optimization of a whole FVF-LDO (Flipped-Voltage-Follower low-dropout regulator) from scratch within the TSMC 180nm CMOS course of. The mannequin needed to dimension the ability transistor, tune the compensation community, and choose bias voltages in order that six metrics land inside spec concurrently — part margin, line regulation, load regulation, quiescent present, PSRR, and transient response. Wired into an ngspice simulation loop, in about an hour of closed-loop iteration — calling the simulator, studying waveforms, tweaking parameters — the mannequin produced a design the place each goal metric is met, with 4 key metrics improved by an order of magnitude over its personal preliminary try.
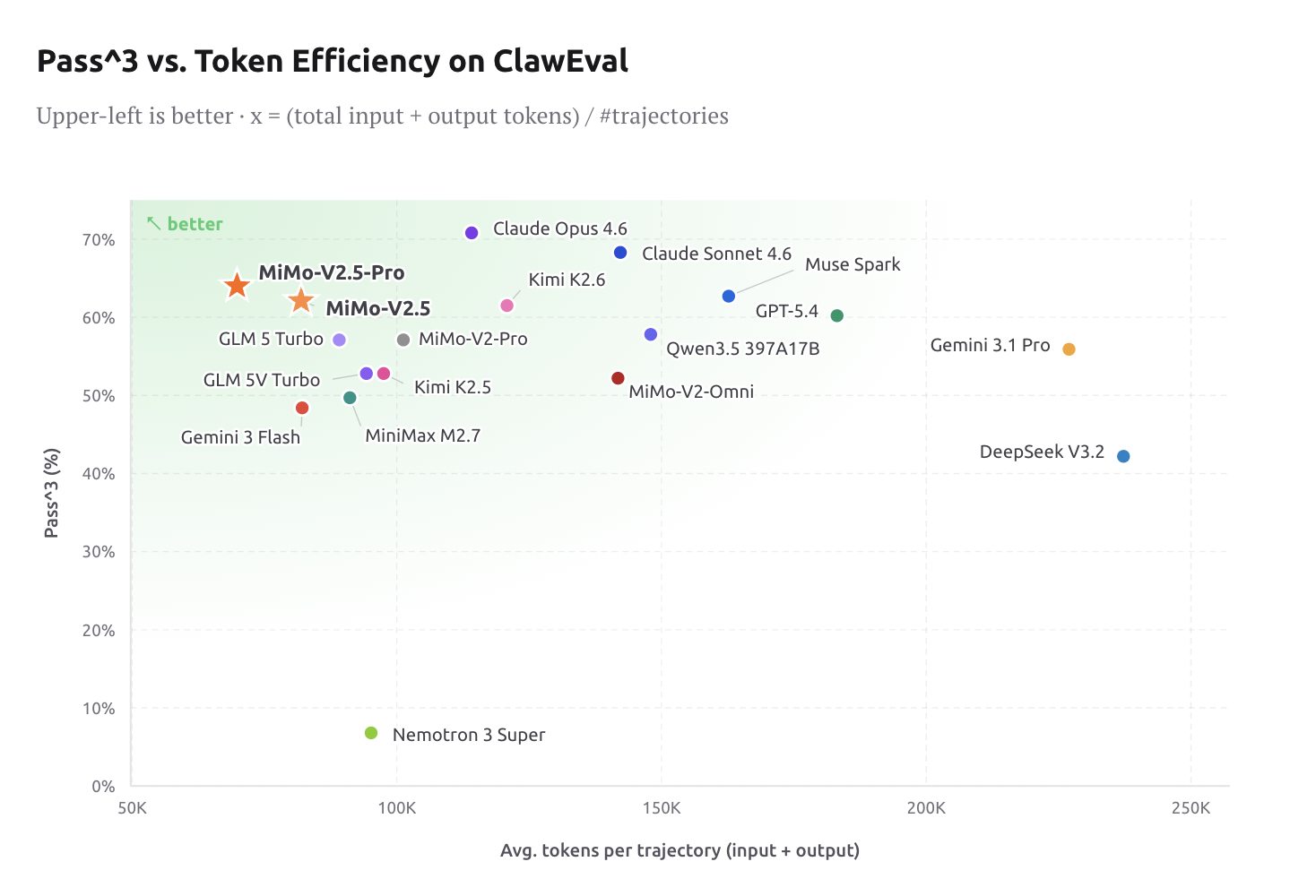
Token Effectivity: Intelligence at frontier stage is barely helpful if it’s cost-effective. On ClawEval, V2.5-Professional lands at 64% Move^3 utilizing solely ~70K tokens per trajectory — roughly 40–60% fewer tokens than Claude Opus 4.6, Gemini 3.1 Professional, and GPT-5.4 at comparable functionality ranges. For engineers constructing manufacturing agent pipelines, this can be a materials price discount, not only a advertising stat.
MiMo Coding Bench is Xiaomi’s in-house analysis suite designed to evaluate fashions on real-world developer duties inside agentic frameworks like Claude Code. It covers repo understanding, challenge constructing, code evaluate, structured artifact era, planning, SWE, and extra. V2.5-Professional leads the sphere on this benchmark, and Xiaomi explicitly positions it as a drop-in backend for scaffolds together with Claude Code, OpenCode, and Kilo.
MiMo-V2.5: Native Omnimodal at Half the Value
Whereas V2.5-Professional targets the toughest long-horizon agentic duties, MiMo-V2.5 is a significant step ahead in agentic functionality and multimodal understanding. With native visible and audio understanding, MiMo-V2.5 causes seamlessly throughout modalities, surpasses MiMo-V2-Professional in agentic efficiency, and helps as much as 1 million tokens of context.
The mannequin is designed with notion and motion unified from scratch. MiMo-V2.5 is educated from the begin to see, hear, and act on what it perceives, resulting in a single mannequin that understands all the pieces and will get issues finished. That is architecturally important — earlier multimodal fashions usually bolted imaginative and prescient on high of a textual content spine, creating functionality gaps on the perception-action boundary.
On the coding facet, the worth proposition is obvious: in MiMo Coding Bench, MiMo-V2.5 delivers sturdy outcomes on on a regular basis coding duties, closing the hole with frontier fashions and matching MiMo-V2.5-Professional at half the fee. For groups that don’t want the acute long-horizon depth of V2.5-Professional, this can be a compelling working level.
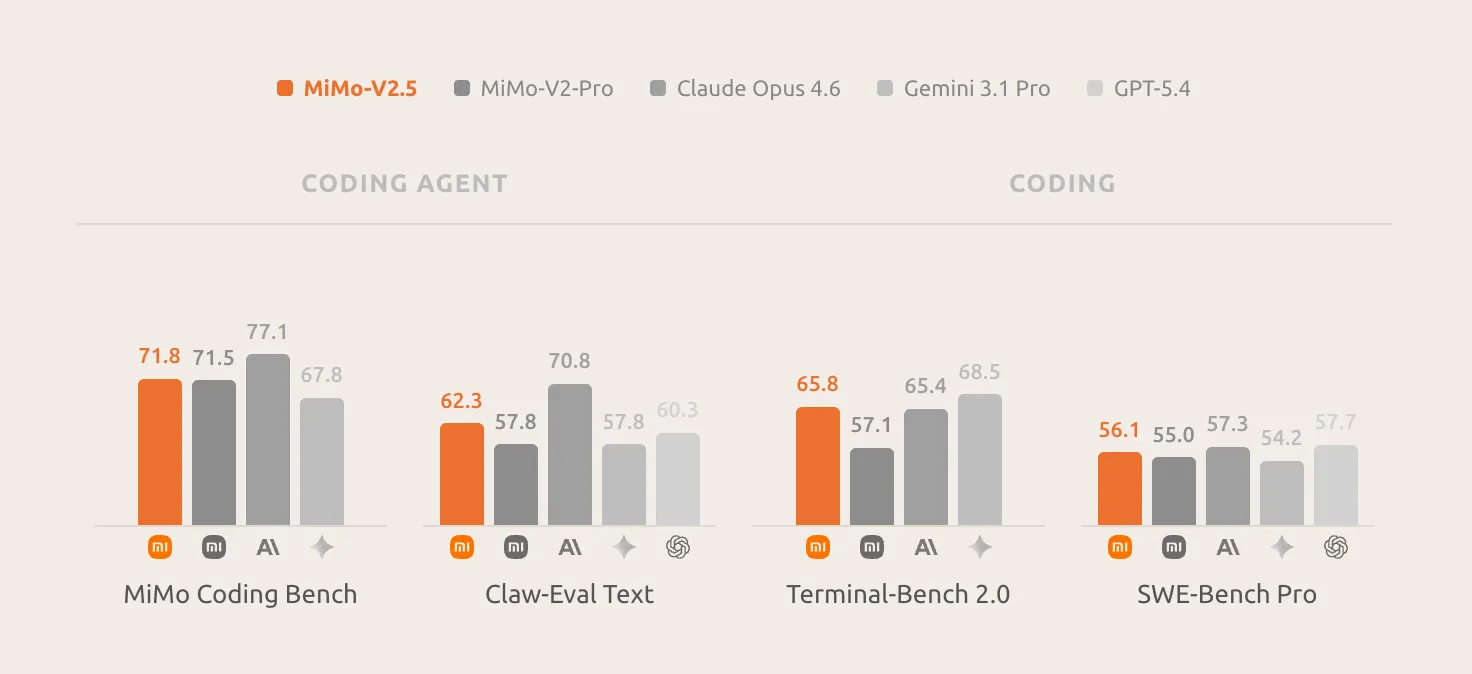
On multimodal benchmarks: MiMo-V2.5 achieves a 62.3 on the Claw-Eval normal subset, putting it on the Pareto frontier of efficiency and effectivity. On the multimodal agentic subset, MiMo-V2.5 reaches 23.8 on Claw-Eval Multimodal, matching Claude Sonnet 4.6, main MiMo-V2-Omni by eight factors, and trailing Claude Opus 4.6 by a single level.
On video understanding, MiMo-V2.5 scores 87.7 on Video-MME, successfully tied with Gemini 3 Professional (88.4) and effectively forward of Gemini 3 Flash. Lengthy-horizon video comprehension — scene monitoring, temporal reasoning, visible grounding over minutes of footage — is now in frontier territory. On picture understanding, MiMo-V2.5 lands at 81.0 on CharXiv RQ and 77.9 on MMMU-Professional, closing in on Gemini 3 Professional.
Pricing is simple: MiMo-V2.5 runs at 1x (1 token = 1 credit score), whereas MiMo-V2.5-Professional runs at 2x (1 token = 2 credit). Token Plans now not cost a multiplier for the 1M-token context window — beforehand a standard price friction for long-context agentic workloads.
Key Takeaways
- MiMo-V2.5-Professional matches frontier closed-source fashions on key agentic benchmarks (SWE-bench Professional 57.2, Claw-Eval 63.8, τ3-Bench 72.9), whereas utilizing 40–60% fewer tokens per trajectory than Claude Opus 4.6, Gemini 3.1 Professional, and GPT-5.4.
- Lengthy-horizon autonomy is actual and measurable — V2.5-Professional autonomously constructed a whole SysY compiler in Rust (233/233 exams, 672 device calls, 4.3 hours) and a full-featured desktop video editor (8,192 traces of code, 1,868 device calls, 11.5 hours).
- MiMo-V2.5 is natively omnimodal — educated from scratch to see, hear, and act throughout modalities with a local 1M-token context window, matching Claude Sonnet 4.6 on Claw-Eval Multimodal and almost tying Gemini 3 Professional on Video-MME (87.7 vs. 88.4).
- Professional-level coding efficiency at half the fee — on MiMo Coding Bench, MiMo-V2.5 matches MiMo-V2.5-Professional on on a regular basis coding duties at 1x token pricing, making it the sensible alternative for many manufacturing agent pipelines.
- Each fashions are already appropriate with common agentic scaffolds like Claude Code, OpenCode, and Kilo — giving AI devs a drop-in, auditable, self-hostable path to frontier-level agentic AI.
Try the Technical particulars MiMo-V2.5, and Technical particulars MiMo-V2.5-Professional. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 130k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Have to associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so forth.? Join with us