
: A Machine Studying Framework that Collectively Regularizes Latents Utilizing a Diffusion Prior and Decoder")
{kind=link}
Generative AI’s present trajectory depends closely on Latent Diffusion Fashions (LDMs) to handle the computational value of high-resolution synthesis. By compressing knowledge right into a lower-dimensional latent area, fashions can scale successfully. Nevertheless, a basic trade-off persists: decrease info density makes latents simpler to be taught however sacrifices reconstruction high quality, whereas larger density allows near-perfect reconstruction however calls for better modeling capability.
Google DeepMind researchers have launched Unified Latents (UL), a framework designed to navigate this trade-off systematically. The framework collectively regularizes latent representations with a diffusion prior and decodes them through a diffusion mannequin.
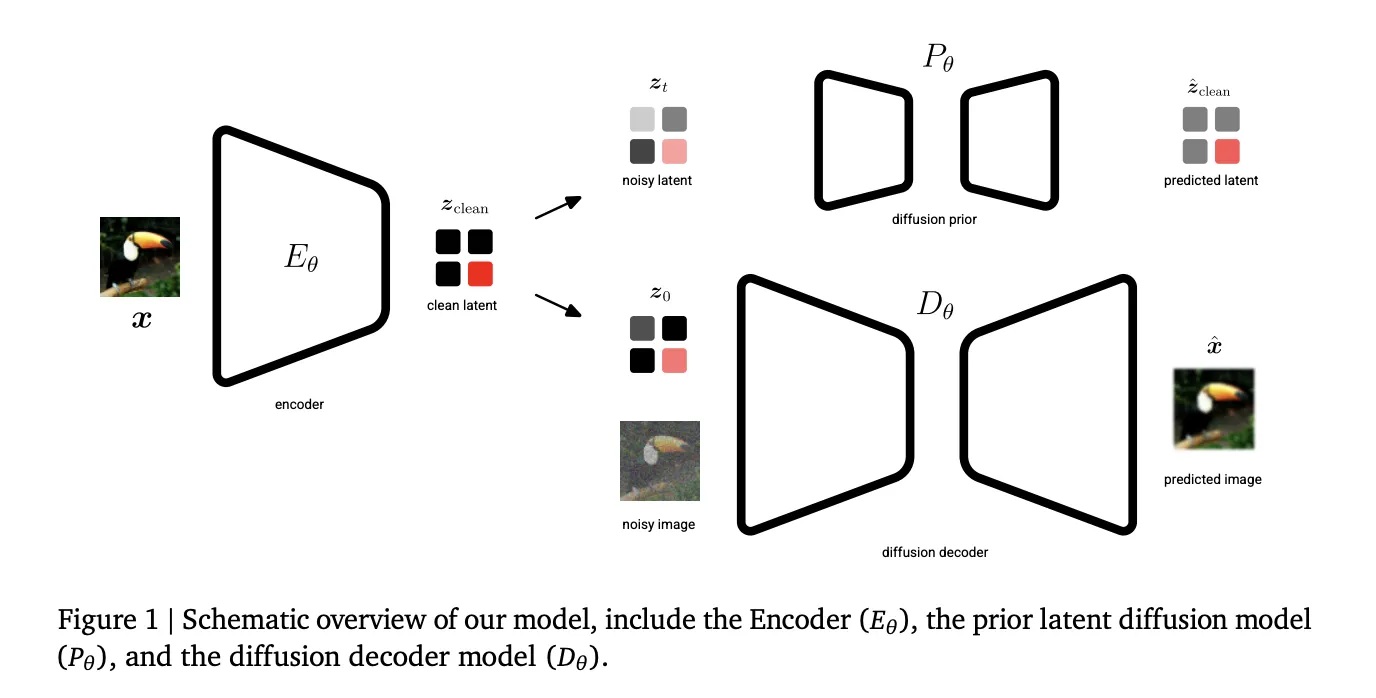
The Structure: Three Pillars of Unified Latents
The Unified Latents (UL) framework rests on three particular technical elements:
- Fastened Gaussian Noise Encoding: Not like customary Variational Autoencoders (VAEs) that be taught an encoder distribution, UL makes use of a deterministic encoder E𝝷 that predicts a single latent zclear. This latent is then forward-noised to a remaining log signal-to-noise ratio (log-SNR) of λ(0)=5.
- Prior-Alignment: The prior diffusion mannequin is aligned with this minimal noise stage. This alignment permits the Kullback-Leibler (KL) time period within the Proof Decrease Certain (ELBO) to cut back to a easy weighted Imply Squared Error (MSE) over noise ranges.
- Reweighted Decoder ELBO: The decoder makes use of a sigmoid-weighted loss, which supplies an interpretable sure on the latent bitrate whereas permitting the mannequin to prioritize completely different noise ranges.
The Two-Stage Coaching Course of
The UL framework is carried out in two distinct levels to optimize each latent studying and era high quality.
Stage 1: Joint Latent Studying
Within the first stage, the encoder, diffusion prior (P𝝷), and diffusion decoder (D𝝷) are educated collectively. The target is to be taught latents which might be concurrently encoded, regularized, and modeled. The encoder’s output noise is linked on to the prior’s minimal noise stage, offering a decent higher sure on the latent bitrate.
Stage 2: Base Mannequin Scaling
The analysis staff discovered {that a} prior educated solely on an ELBO loss in Stage 1 doesn’t produce optimum samples as a result of it weights low-frequency and high-frequency content material equally. Consequently, in Stage 2, the encoder and decoder are frozen. A brand new ‘base mannequin’ is then educated on the latents utilizing a sigmoid weighting, which considerably improves efficiency. This stage permits for bigger mannequin sizes and batch sizes.
Technical Efficiency and SOTA Benchmarks
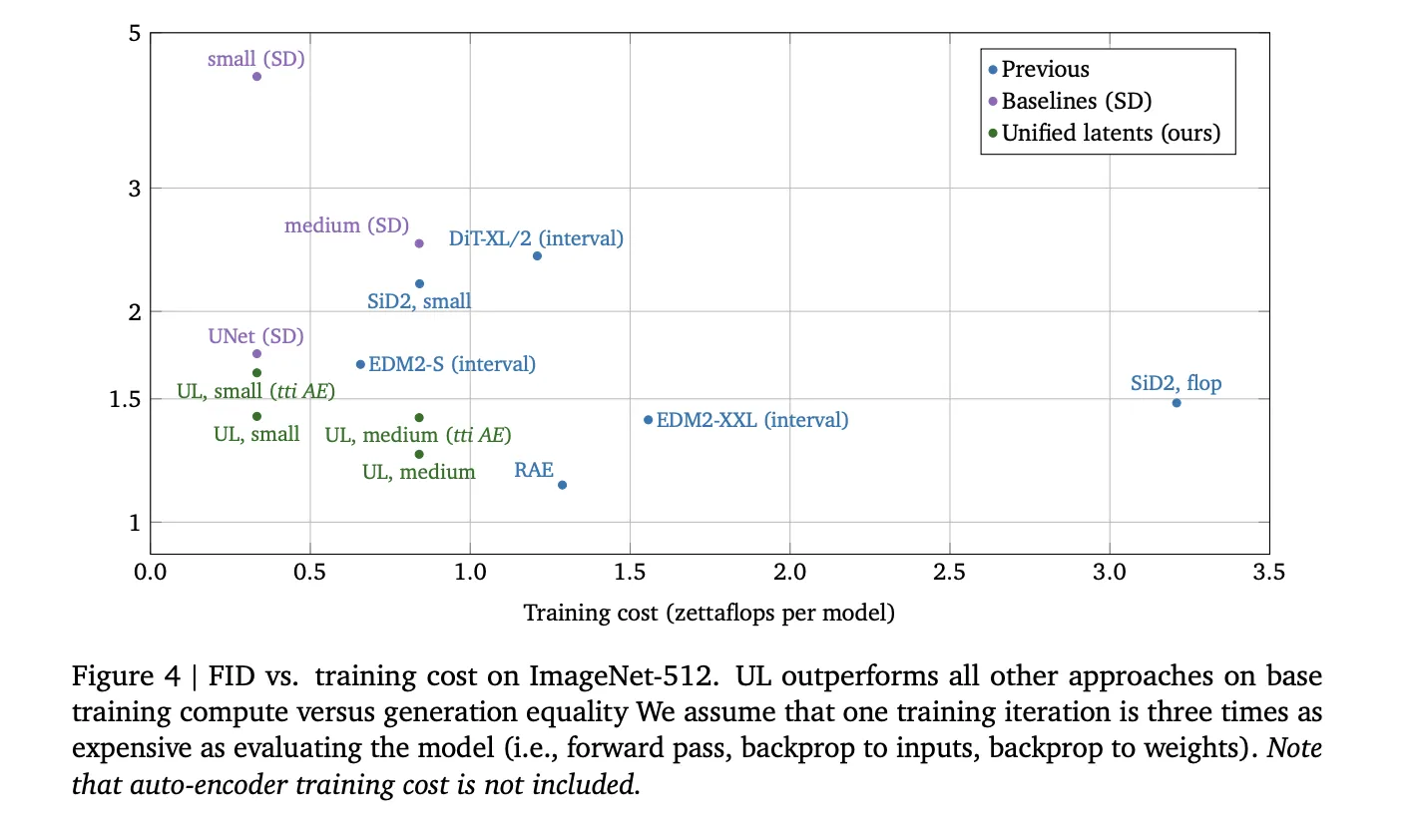
Unified Latents reveal excessive effectivity within the relationship between coaching compute (FLOPs) and era high quality.
| Metric | Dataset | Consequence | Significance |
| FID | ImageNet-512 | 1.4 | Outperforms fashions educated on Secure Diffusion latents for a given compute finances. |
| FVD | Kinetics-600 | 1.3 | Units a brand new State-of-the-Artwork (SOTA) for video era. |
| PSNR | ImageNet-512 | As much as 30.1 | Maintains excessive reconstruction constancy even at larger compression ranges. |
On ImageNet-512, UL outperformed earlier approaches, together with DiT and EDM2 variants, when it comes to coaching value versus era FID. In video duties utilizing Kinetics-600, a small UL mannequin achieved a 1.7 FVD, whereas the medium variant reached the SOTA 1.3 FVD.
Key Takeaways
- Built-in Diffusion Framework: UL is a framework that collectively optimizes an encoder, a diffusion prior, and a diffusion decoder, making certain that latent representations are concurrently encoded, regularized, and modeled for high-efficiency era.
- Fastened-Noise Info Certain: Through the use of a deterministic encoder that provides a set quantity of Gaussian noise (particularly at a log-SNR of λ(0)=5) and linking it to the prior’s minimal noise stage, the mannequin supplies a decent, interpretable higher sure on the latent bitrate.
- Two-Stage Coaching Technique: The method includes an preliminary joint coaching stage for the autoencoder and prior, adopted by a second stage the place the encoder and decoder are frozen and a bigger ‘base mannequin’ is educated on the latents to maximise pattern high quality.
- State-of-the-Artwork Efficiency: The framework established a brand new state-of-the-art (SOTA) Fréchet Video Distance (FVD) of 1.3 on Kinetics-600 and achieved a aggressive Fréchet Inception Distance (FID) of 1.4 on ImageNet-512 whereas requiring fewer coaching FLOPs than customary latent diffusion baselines.
Take a look at the Paper. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.
