

{kind=link}
Automated speech recognition (ASR) is changing into a core constructing block for AI merchandise, from assembly instruments to voice brokers. Mistral’s new Voxtral Transcribe 2 household targets this house with 2 fashions that cut up cleanly into batch and realtime use circumstances, whereas protecting value, latency, and deployment constraints in focus.
The discharge contains:
- Voxtral Mini Transcribe V2 for batch transcription with diarization.
- Voxtral Realtime (Voxtral Mini 4B Realtime 2602) for low-latency streaming transcription, launched as open weights.
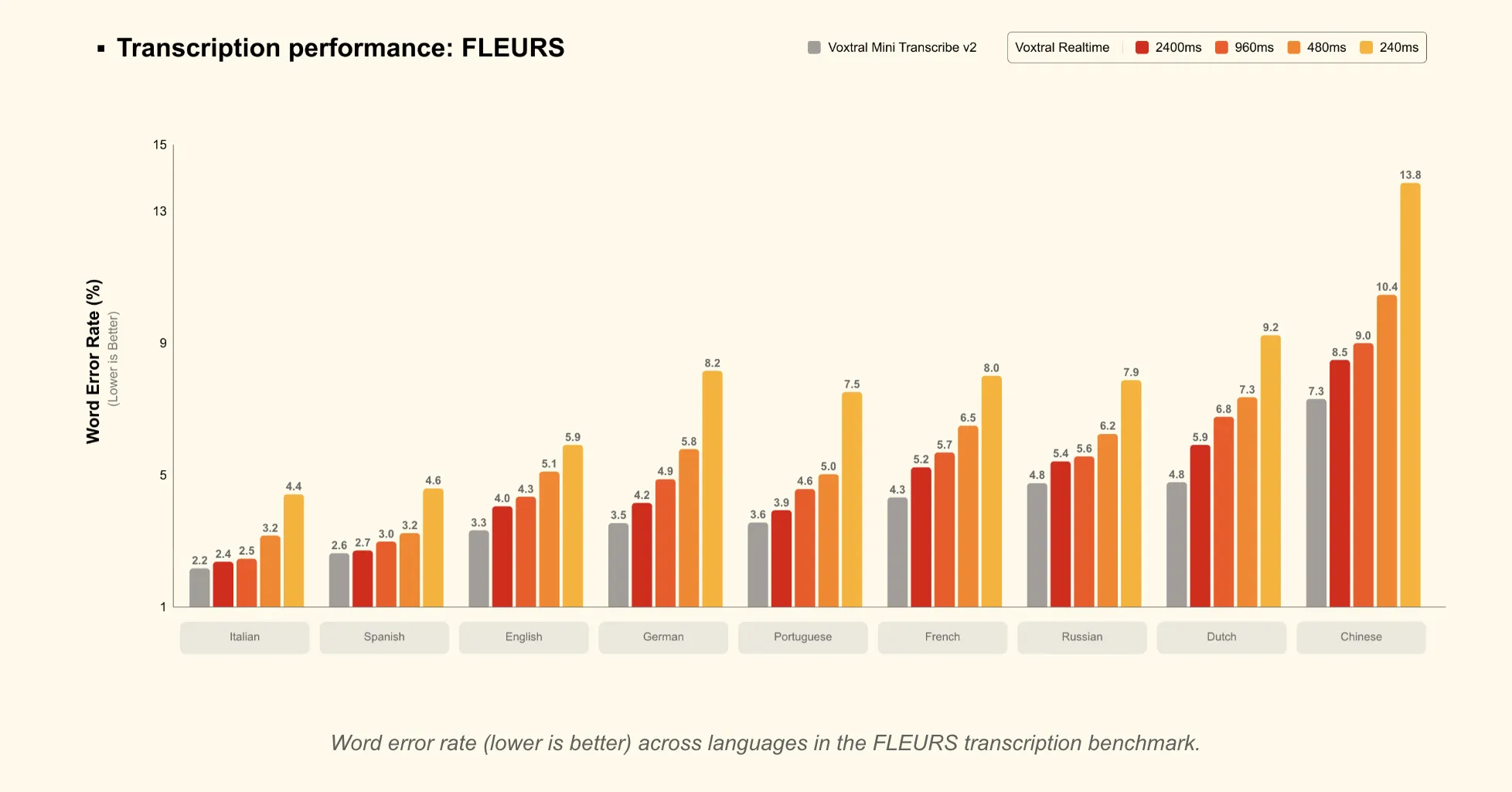
Each fashions are designed for 13 languages: English, Chinese language, Hindi, Spanish, Arabic, French, Portuguese, Russian, German, Japanese, Korean, Italian, and Dutch.
Mannequin household: batch and streaming, with clear roles
Mistral positions Voxtral Transcribe 2 as ‘two next-generation speech-to-text fashions’ with state-of-the-art transcription high quality, diarization, and ultra-low latency.
- Voxtral Mini Transcribe V2 is the batch mannequin. It’s optimized for transcription high quality and diarization throughout domains and languages and uncovered as an environment friendly audio enter mannequin within the Mistral API.
- Voxtral Realtime is the streaming mannequin. It’s constructed with a devoted streaming structure and is launched as an open-weights mannequin underneath Apache 2.0 on Hugging Face, with a really helpful vLLM runtime.
A key element: speaker diarization is offered by Voxtral Mini Transcribe V2, not by Voxtral Realtime. Realtime focuses strictly on quick, correct streaming transcription.
Voxtral Realtime: 4B-parameter streaming ASR with configurable delay
Voxtral Mini 4B Realtime 2602 is a 4B-parameter multilingual realtime speech-transcription mannequin. It’s among the many first open-weights fashions to succeed in accuracy corresponding to offline programs with a delay underneath 500 ms.
Structure:
- ≈3.4B-parameter language mannequin.
- ≈0.6B-parameter audio encoder.
- The audio encoder is educated from scratch with causal consideration.
- Each encoder and LM use sliding-window consideration, enabling successfully “infinite” streaming.
Latency vs accuracy is explicitly configurable:
- Transcription delay is tunable from 80 ms to 2.4 s by way of a
transcription_delay_msparameter. - The Mistral describes latency as “configurable right down to sub-200 ms” for stay functions.
- At 480 ms delay, Realtime matches main offline open-source transcription fashions and realtime APIs on benchmarks akin to FLEURS and long-form English.
- At 2.4 s delay, Realtime matches Voxtral Mini Transcribe V2 on FLEURS, which is suitable for subtitling duties the place barely larger latency is appropriate.
From a deployment standpoint:
- The mannequin is launched in BF16 and is designed for on-device or edge deployment.
- It could possibly run in realtime on a single GPU with ≥16 GB reminiscence, in accordance with the vLLM serving directions within the mannequin card.
The primary management knob is the delay setting:
- Decrease delays (≈80–200 ms) for interactive brokers the place responsiveness dominates.
- Round 480 ms because the really helpful “candy spot” between latency and accuracy.
- Larger delays (as much as 2.4 s) whenever you want accuracy as shut as potential to the batch mannequin.
Voxtral Mini Transcribe V2: batch ASR with diarization and context biasing
Voxtral Mini Transcribe V2 is a closed-weights audio enter mannequin optimized just for transcription. It’s uncovered within the Mistral API as voxtral-mini-2602 at $0.003 per minute.
On benchmarks and pricing:
- Round 4% phrase error fee (WER) on the FLEURS transcription benchmark, averaged excessive 10 languages.
- “Greatest price-performance of any transcription API” at $0.003/min.
- Outperforms GPT-4o mini Transcribe, Gemini 2.5 Flash, Meeting Common, and Deepgram Nova on accuracy of their comparisons.
- Processes audio ≈3× sooner than ElevenLabs’ Scribe v2 whereas matching high quality at one-fifth the associated fee.
Enterprise-oriented options are concentrated on this mannequin:
- Speaker diarization
- Outputs speaker labels with exact begin and finish instances.
- Designed for conferences, interviews, and multi-party calls.
- For overlapping speech, the mannequin sometimes emits a single speaker label.
- Context biasing
- Accepts as much as 100 phrases or phrases to bias transcription towards particular names or area phrases.
- Optimized for English, with experimental assist for different languages.
- Phrase-level timestamps
- Per-word begin and finish timestamps for subtitles, alignment, and searchable audio workflows.
- Noise robustness
- Maintains accuracy in noisy environments akin to manufacturing facility flooring, name facilities, and discipline recordings.
- Longer audio assist
- Handles as much as 3 hours of audio in a single request.
Language protection mirrors Realtime: 13 languages, with Mistral noting that non-English efficiency “considerably outpaces opponents” of their analysis.
APIs, tooling, and deployment choices
The mixing paths are easy and differ barely between the 2 fashions:
- Voxtral Mini Transcribe V2
- Served by way of the Mistral audio transcription API (
/v1/audio/transcriptions) as an environment friendly transcription-only service. - Priced at $0.003/min. (Mistral AI)
- Accessible in Mistral Studio’s audio playground and in Le Chat for interactive testing.
- Served by way of the Mistral audio transcription API (
- Voxtral Realtime
- Accessible by way of the Mistral API at $0.006/min.
- Launched as open weights on Hugging Face (
mistralai/Voxtral-Mini-4B-Realtime-2602) underneath Apache 2.0, with official vLLM Realtime assist.
The audio playground in Mistral Studio lets customers:
- Add as much as 10 audio information (.mp3, .wav, .m4a, .flac, .ogg) as much as 1 GB every.
- Toggle diarization, select timestamp granularity, and configure context bias phrases.
Key Takeaways
- Two-model household with clear roles: Voxtral Mini Transcribe V2 targets batch transcription and diarization, whereas Voxtral Realtime targets low-latency streaming ASR, each throughout 13 languages.
- Realtime model- 4B parameters with tunable delay: Voxtral Realtime makes use of a 4B structure (≈3.4B LM + ≈0.6B encoder) with sliding-window and causal consideration, and helps configurable transcription delay from 80 ms to 2.4 s.
- Latency vs accuracy trade-off is specific: Round 480 ms delay, Voxtral Realtime reaches accuracy corresponding to robust offline and realtime programs, and at 2.4 s it matches Voxtral Mini Transcribe V2 on FLEURS.
- Batch mannequin provides diarization and enterprise options: Voxtral Mini Transcribe V2 gives diarization, context biasing with as much as 100 phrases, word-level timestamps, noise robustness, and helps as much as 3 hours of audio per request at $0.003/min.
- Deployment- closed batch API, open realtime weights: Mini Transcribe V2 is served by way of Mistral’s audio transcription API and playground, whereas Voxtral Realtime is priced at $0.006/min and in addition accessible as Apache 2.0 open weights with official vLLM Realtime assist.
Try the Technical particulars and Mannequin Weights. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be part of us on telegram as nicely.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling advanced datasets into actionable insights.
