

{kind=link}
Why are AI dev groups nonetheless coaching and storing a number of massive language fashions for various deployment wants when one elastic mannequin can generate a number of sizes on the identical price? NVIDIA is collapsing the standard ‘mannequin household’ stack right into a single coaching job. NVIDIA AI group releases Nemotron-Elastic-12B, a 12B parameter reasoning mannequin that embeds nested 9B and 6B variants in the identical parameter area, so all three sizes come from one elastic checkpoint with no further distillation runs per dimension.
Many in a single mannequin household
Most manufacturing programs want a number of mannequin sizes, a bigger mannequin for server facet workloads, a mid dimension mannequin for sturdy edge GPUs, and a smaller mannequin for tight latency or energy budgets. The same old pipeline trains or distills every dimension individually, so token price and checkpoint storage scale with the variety of variants.
Nemotron Elastic takes a distinct route. It begins from the Nemotron Nano V2 12B reasoning mannequin and trains an elastic hybrid Mamba Consideration community that exposes a number of nested submodels. The launched Nemotron-Elastic-12B checkpoint will be sliced into 9B and 6B variants, Nemotron-Elastic-9B and Nemotron-Elastic-6B, utilizing a offered slicing script, with none further optimization.
All variants share weights and routing metadata, so coaching price and deployment reminiscence are tied to the most important mannequin, to not the variety of sizes within the household.
Hybrid Mamba Transformer with elastic masks
Architecturally, Nemotron Elastic is a Mamba-2 Transformer hybrid. The bottom community follows the Nemotron-H type design, the place most layers are Mamba-2 primarily based sequence state area blocks plus MLP, and a small set of consideration layers protect world receptive discipline.
Elasticity is applied by turning this hybrid right into a dynamic mannequin managed by masks:
- Width, embedding channels, Mamba heads and head channels, consideration heads, and FFN intermediate dimension will be lowered by binary masks.
- Depth, layers will be dropped in accordance with a discovered significance ordering, with residual paths preserving sign stream.
A router module outputs discrete configuration selections per funds. These selections are transformed to masks with Gumbel Softmax, then utilized to embeddings, Mamba projections, consideration projections, and FFN matrices. The analysis group provides a number of particulars to maintain the SSM construction legitimate:
- Group conscious SSM elastification that respects Mamba head and channel grouping.
- Heterogeneous MLP elastification the place completely different layers can have distinct intermediate sizes.
- Normalized MSE primarily based layer significance to determine which layers keep when depth is lowered.
Smaller variants are at all times prefix picks within the ranked element lists, which makes the 6B and 9B fashions true nested subnetworks of the 12B mother or father.
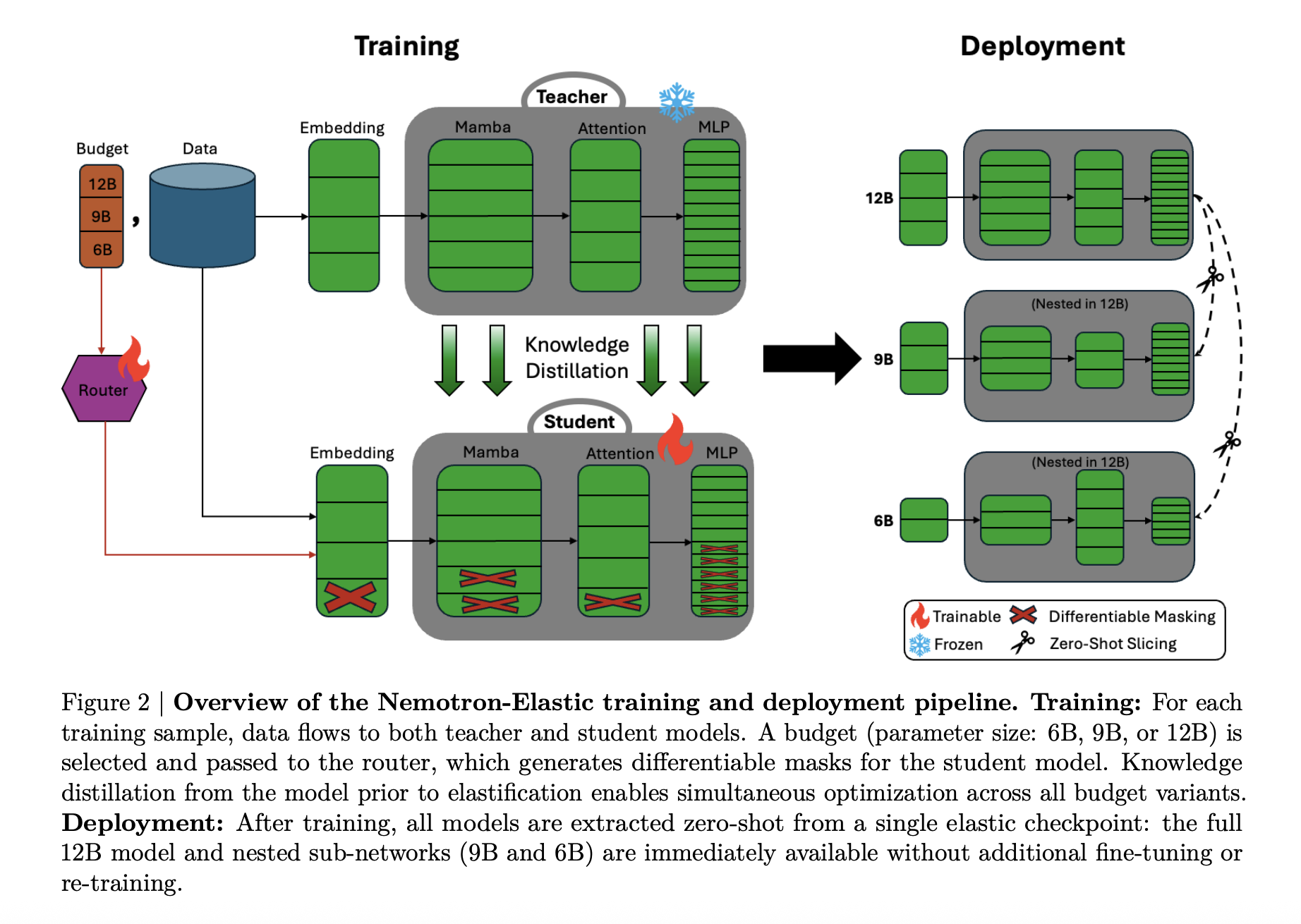
Two stage coaching for reasoning workloads
Nemotron Elastic is educated as a reasoning mannequin with a frozen trainer. The trainer is the unique Nemotron-Nano-V2-12B reasoning mannequin. The elastic-12B scholar is optimized collectively for all three budgets, 6B, 9B, 12B, utilizing information distillation plus language modeling loss.
Coaching runs in two levels:
- Stage 1: brief context, sequence size 8192, batch dimension 1536, round 65B tokens, with uniform sampling over the three budgets.
- Stage 2: prolonged context, sequence size 49152, batch dimension 512, round 45B tokens, with non uniform sampling that favors the total 12B funds.
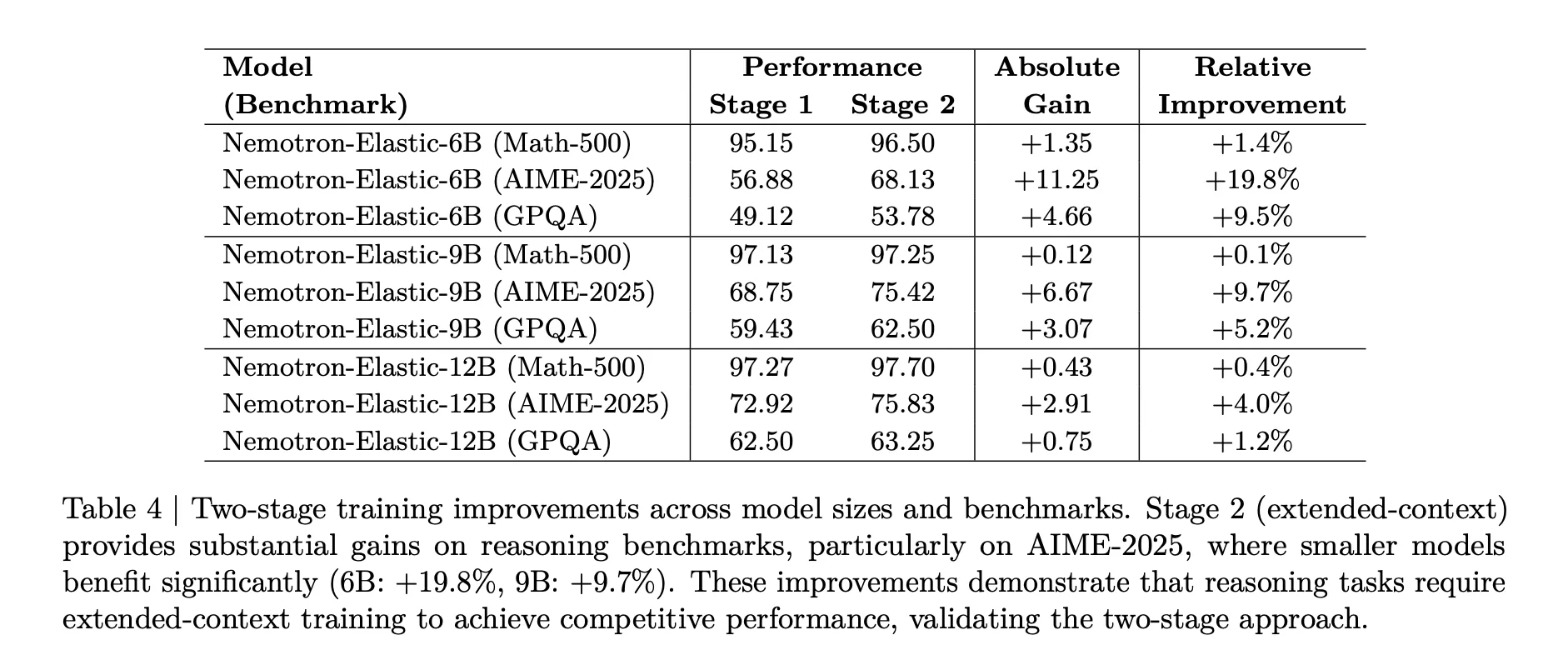
The second stage is necessary for reasoning duties. The above desk exhibits that for AIME 2025, the 6B mannequin improves from 56.88 to 68.13, a 19.8 p.c relative acquire, whereas the 9B mannequin positive factors 9.7 p.c and the 12B mannequin positive factors 4.0 p.c after prolonged context coaching.
Finances sampling can be tuned. In Stage 2, non uniform weights of 0.5, 0.3, 0.2 for 12B, 9B, 6B keep away from degradation of the most important mannequin and maintain all variants aggressive on Math 500, AIME 2025, and GPQA.
Benchmark outcomes
Nemotron Elastic is evaluated on reasoning heavy benchmarks, MATH 500, AIME 2024, AIME 2025, GPQA, LiveCodeBench v5, and MMLU Professional. The beneath desk summarizes move at 1 accuracy.

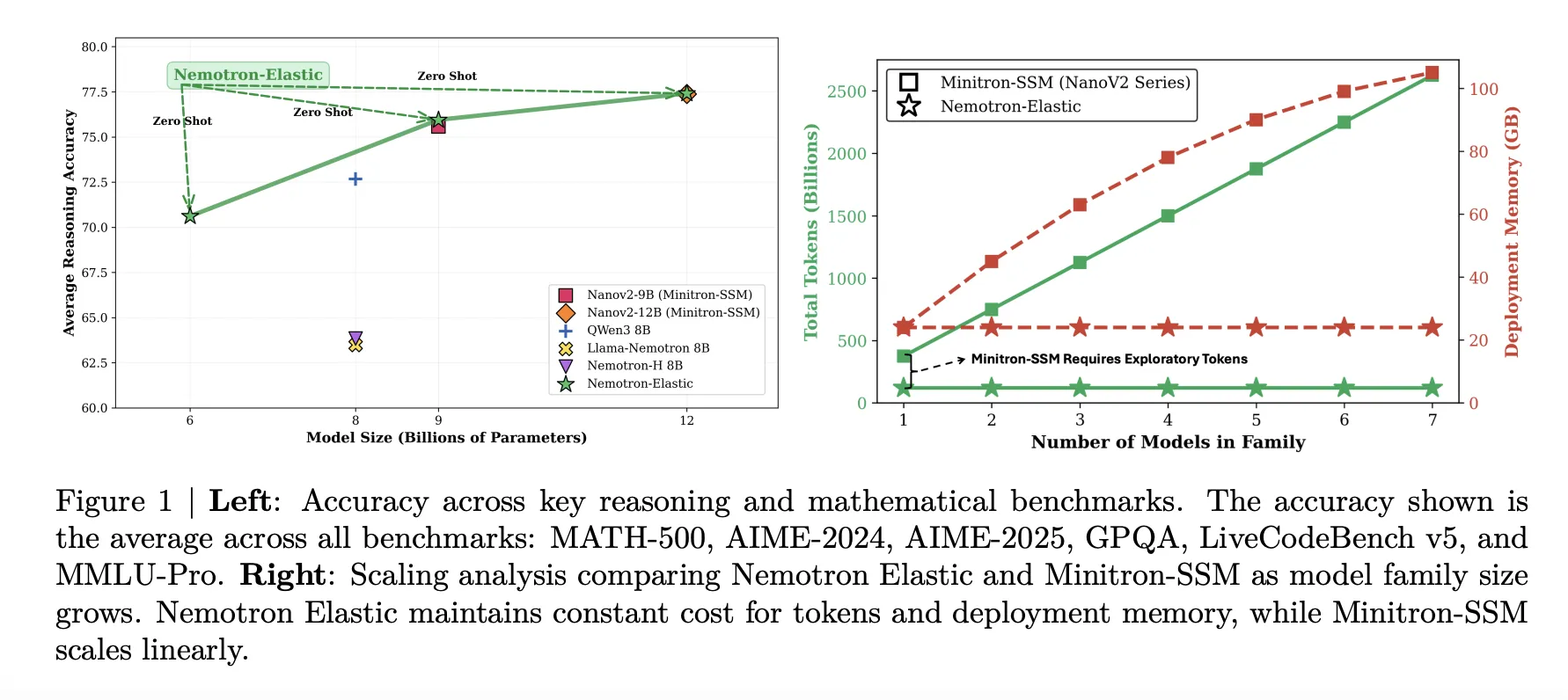
The 12B elastic mannequin matches the NanoV2-12B baseline on common, 77.41 versus 77.38, whereas additionally offering 9B and 6B variants from the identical run. The 9B elastic mannequin tracks the NanoV2-9B baseline intently, 75.95 versus 75.99. The 6B elastic mannequin reaches 70.61, barely beneath Qwen3-8B at 72.68 however nonetheless sturdy for its parameter depend on condition that it’s not educated individually.
Coaching token and reminiscence financial savings
Nemotron Elastic targets the price downside straight. The beneath desk compares the token budgets wanted to derive 6B and 9B fashions from a 12B mother or father:
- NanoV2 pretraining for 6B and 9B, 40T tokens complete.
- NanoV2 Compression with Minitron SSM, 480B exploratory plus 270B closing, 750B tokens.
- Nemotron Elastic, 110B tokens in a single elastic distillation run.
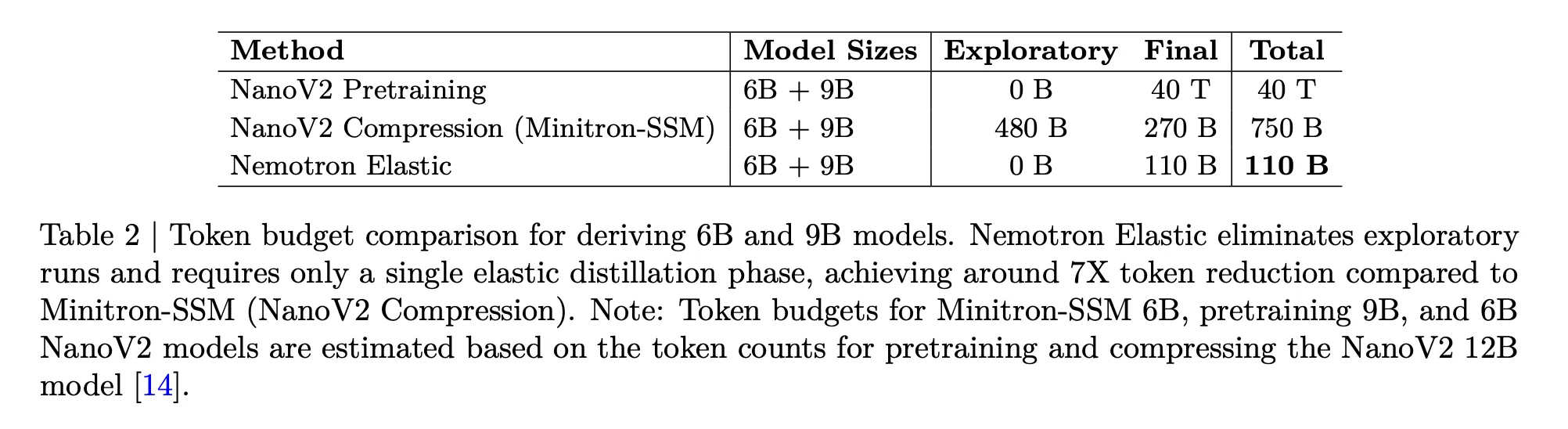
The analysis group experiences that this offers round 360 instances discount versus coaching the 2 further fashions from scratch, and round 7 instances discount versus the compression baseline.
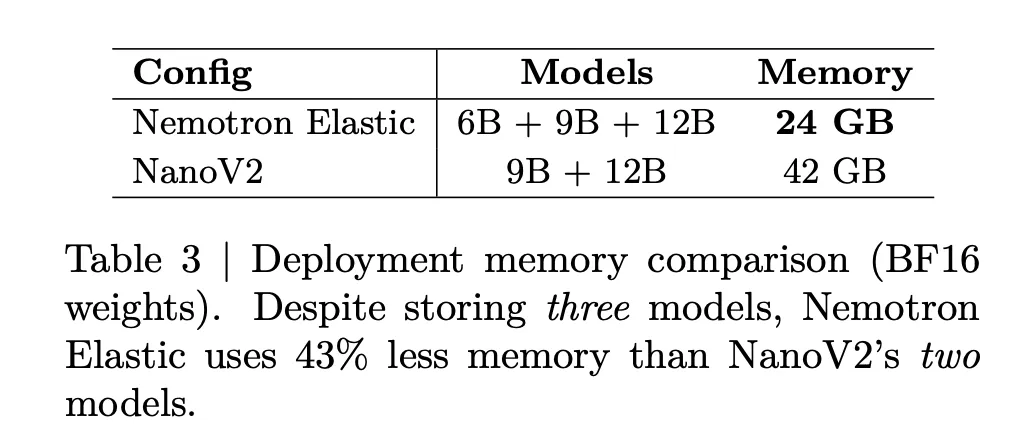
Deployment reminiscence is lowered as effectively. The beneath desk states that storing Nemotron Elastic 6B, 9B, and 12B collectively requires 24GB of BF16 weights, whereas storing NanoV2 9B plus 12B requires 42GB. This can be a 43 p.c reminiscence discount whereas additionally exposing an additional 6B dimension.
Comparability
| System | Sizes (B) | Avg reasoning rating* | Tokens for 6B + 9B | BF16 reminiscence |
|---|---|---|---|---|
| Nemotron Elastic | 6, 9, 12 | 70.61 / 75.95 / 77.41 | 110B | 24GB |
| NanoV2 Compression | 9, 12 | 75.99 / 77.38 | 750B | 42GB |
| Qwen3 | 8 | 72.68 | n / a | n / a |
Key Takeaways
- Nemotron Elastic trains one 12B reasoning mannequin that comprises nested 9B and 6B variants which will be extracted zero shot with out further coaching.
- The elastic household makes use of a hybrid Mamba-2 and Transformer structure plus a discovered router that applies structured masks over width and depth to outline every submodel.
- The method wants 110B coaching tokens to derive 6B and 9B from the 12B mother or father which is about 7 instances fewer tokens than the 750B token Minitron SSM compression baseline and about 360 instances fewer than coaching further fashions from scratch.
- On reasoning benchmarks similar to MATH 500, AIME 2024 and 2025, GPQA, LiveCodeBench and MMLU Professional the 6B, 9B and 12B elastic fashions attain common scores of about 70.61, 75.95 and 77.41 that are on par with or near the NanoV2 baselines and aggressive with Qwen3-8B.
- All three sizes share one 24GB BF16 checkpoint so deployment reminiscence stays fixed for the household in contrast with round 42GB for separate NanoV2-9B and 12B fashions which provides about 43 p.c reminiscence financial savings whereas including a 6B possibility.
Nemotron-Elastic-12B is a sensible step towards making reasoning mannequin households cheaper to construct and function. One elastic checkpoint produces 6B, 9B, and 12B variants with a hybrid Mamba-2 and Transformer structure, a discovered router, and structured masks that protect reasoning efficiency. The method cuts token price relative to separate compression or pretraining runs and retains deployment reminiscence at 24GB for all sizes, which simplifies fleet administration for multi tier LLM deployments. Total, Nemotron-Elastic-12B turns multi dimension reasoning LLMs right into a single elastic programs design downside.
Take a look at the Paper and Mannequin weights. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.