

{kind=link}
Tuning LLM outputs is essentially a decoding drawback: you form the mannequin’s next-token distribution with a handful of sampling controls—max tokens (caps response size below the mannequin’s context restrict), temperature (logit scaling for extra/much less randomness), top-p/nucleus and top-k (truncate the candidate set by chance mass or rank), frequency and presence penalties (discourage repetition or encourage novelty), and cease sequences (laborious termination on delimiters). These seven parameters work together: temperature widens the tail that top-p/top-k then crop; penalties mitigate degeneration throughout lengthy generations; cease plus max tokens supplies deterministic bounds. The sections under outline every parameter exactly and summarize vendor-documented ranges and behaviors grounded within the decoding literature.
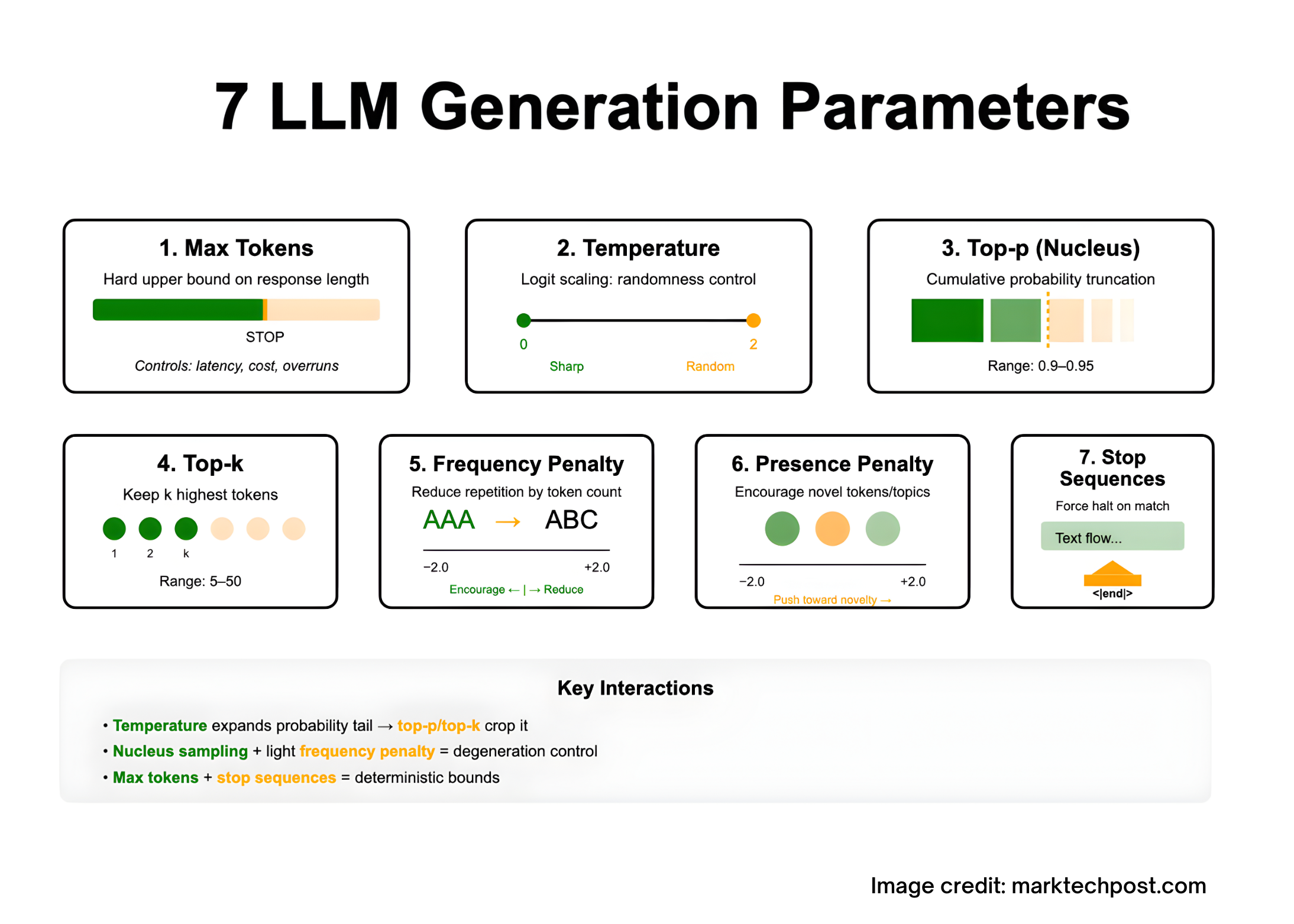
1) Max tokens (a.okay.a. max_tokens, max_output_tokens, max_new_tokens)
What it’s: A tough higher sure on what number of tokens the mannequin could generate on this response. It doesn’t develop the context window; the sum of enter tokens and output tokens should nonetheless match inside the mannequin’s context size. If the restrict hits first, the API marks the response “incomplete/size.”
When to tune:
- Constrain latency and price (tokens ≈ time and $$).
- Forestall overruns previous a delimiter once you can not rely solely on
cease.
2) Temperature (temperature)
What it’s: A scalar utilized to logits earlier than softmax:
softmax(z/T)i=∑jezj/Tezi/T
Decrease T sharpens the distribution (extra deterministic); greater T flattens it (extra random). Typical public APIs expose a spread close to [0,2][0, 2][0,2]. Use low T for analytical duties and greater T for inventive growth.
3) Nucleus sampling (top_p)
What it’s: Pattern solely from the smallest set of tokens whose cumulative chance mass ≥ p. This truncates the lengthy low-probability tail that drives basic “degeneration” (rambling, repetition). Launched as nucleus sampling by Holtzman et al. (2019).
Sensible notes:
- Widespread operational band for open-ended textual content is
top_p ≈ 0.9–0.95(Hugging Face steerage). - Anthropic advises tuning both
temperatureortop_p, not each, to keep away from coupled randomness.
4) High-k sampling (top_k)
What it’s: At every step, prohibit candidates to the okay highest-probability tokens, renormalize, then pattern. Earlier work (Fan, Lewis, Dauphin, 2018) used this to enhance novelty vs. beam search. In trendy toolchains it’s usually mixed with temperature or nucleus sampling.
Sensible notes:
- Typical
top_kranges are small (≈5–50) for balanced range; HF docs present this as “pro-tip” steerage. - With each
top_kandtop_pset, many libraries apply k-filtering then p-filtering (implementation element, however helpful to know).
5) Frequency penalty (frequency_penalty)
What it’s: Decreases the chance of tokens proportionally to how usually they already appeared within the generated context, decreasing verbatim repetition. Azure/OpenAI reference specifies the vary −2.0 to +2.0 and defines the impact exactly. Optimistic values scale back repetition; unfavorable values encourage it.
When to make use of: Lengthy generations the place the mannequin loops or echoes phrasing (e.g., bullet lists, poetry, code feedback).
6) Presence penalty (presence_penalty)
What it’s: Penalizes tokens which have appeared not less than as soon as to this point, encouraging the mannequin to introduce new tokens/matters. Identical documented vary −2.0 to +2.0 in Azure/OpenAI reference. Optimistic values push towards novelty; unfavorable values condense round seen matters.
Tuning heuristic: Begin at 0; nudge presence_penalty upward if the mannequin stays too “on-rails” and gained’t discover alternate options.
7) Cease sequences (cease, stop_sequences)
What it’s: Strings that pressure the decoder to halt precisely once they seem, with out emitting the cease textual content. Helpful for bounding structured outputs (e.g., finish of JSON object or part). Many APIs permit a number of cease strings.
Design ideas: Choose unambiguous delimiters unlikely to happen in regular textual content (e.g., "<|finish|>", "nn###"), and pair with max_tokens as a belt-and-suspenders management.
Interactions that matter
- Temperature vs. Nucleus/High-k: Elevating temperature expands chance mass into the tail;
top_p/top_kthen crop that tail. Many suppliers suggest adjusting one randomness management at a time to maintain the search house interpretable. - Degeneration management: Empirically, nucleus sampling alleviates repetition and blandness by truncating unreliable tails; mix with gentle frequency penalty for lengthy outputs.
- Latency/value:
max_tokensis probably the most direct lever; streaming the response doesn’t change value however improves perceived latency. ( - Mannequin variations: Some “reasoning” endpoints prohibit or ignore these knobs (temperature, penalties, and so forth.). Verify model-specific docs earlier than porting configs.
References:
- https://arxiv.org/abs/1904.09751
- https://openreview.web/discussion board?id=rygGQyrFvH
- https://huggingface.co/docs/transformers/en/generation_strategies
- https://huggingface.co/docs/transformers/en/main_classes/text_generation
- https://arxiv.org/abs/1805.04833
- https://aclanthology.org/P18-1082.pdf
- https://assist.openai.com/en/articles/5072263-how-do-i-use-stop-sequences
- https://platform.openai.com/docs/api-reference/introduction
- https://docs.aws.amazon.com/bedrock/newest/userguide/model-parameters-anthropic-claude-messages-request-response.html
- https://cloud.google.com/vertex-ai/generative-ai/docs/multimodal/content-generation-parameters
- https://cloud.google.com/vertex-ai/generative-ai/docs/study/prompts/adjust-parameter-values
- https://study.microsoft.com/en-us/azure/ai-foundry/openai/how-to/reasoning

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.