
: A Tiny 7M Mannequin that Surpass DeepSeek-R1, Gemini 2.5 professional, and o3-mini at Reasoning on each ARG-AGI 1 and ARC-AGI 2")
{kind=link}
Can an iterative draft–revise solver that repeatedly updates a latent scratchpad outperform far bigger autoregressive LLMs on ARC-AGI? Samsung SAIT (Montreal) has launched Tiny Recursive Mannequin (TRM)—a two-layer, ~7M-parameter recursive reasoner that stories 44.6–45% check accuracy on ARC-AGI-1 and 7.8–8% on ARC-AGI-2, surpassing outcomes reported for considerably bigger language fashions resembling DeepSeek-R1, o3-mini-high, and Gemini 2.5 Professional on the identical public evaluations. TRM additionally improves puzzle benchmarks Sudoku-Excessive (87.4%) and Maze-Exhausting (85.3%) over the prior Hierarchical Reasoning Mannequin (HRM, 27M params), whereas utilizing far fewer parameters and a less complicated coaching recipe.
What’s precisely is new?
TRM removes HRM’s two-module hierarchy and fixed-point gradient approximation in favor of a single tiny community that recurses on a latent “scratchpad” (z) and a present answer embedding (y):
- Single tiny recurrent core. Replaces HRM’s two-module hierarchy with one 2-layer community that collectively maintains a latent scratchpad 𝑧 z and a present answer embedding 𝑦 y. The mannequin alternates: suppose: replace 𝑧 ← 𝑓 ( 𝑥 , 𝑦 , 𝑧 ) z←f(x,y,z) for 𝑛 n internal steps; act: replace 𝑦 ← 𝑔 ( 𝑦 , 𝑧 ) y←g(y,z).
- Deeply supervised recursion. The suppose→act block is unrolled as much as 16 occasions with deep supervision and a realized halting head used throughout coaching (full unroll at check time). Indicators are carried throughout steps through (y,z)(y, z)(y,z).
- Full backprop by means of the loop. In contrast to HRM’s one-step implicit (fixed-point) gradient approximation, TRM backpropagates by means of all recursive steps, which the analysis crew discover important for generalization.
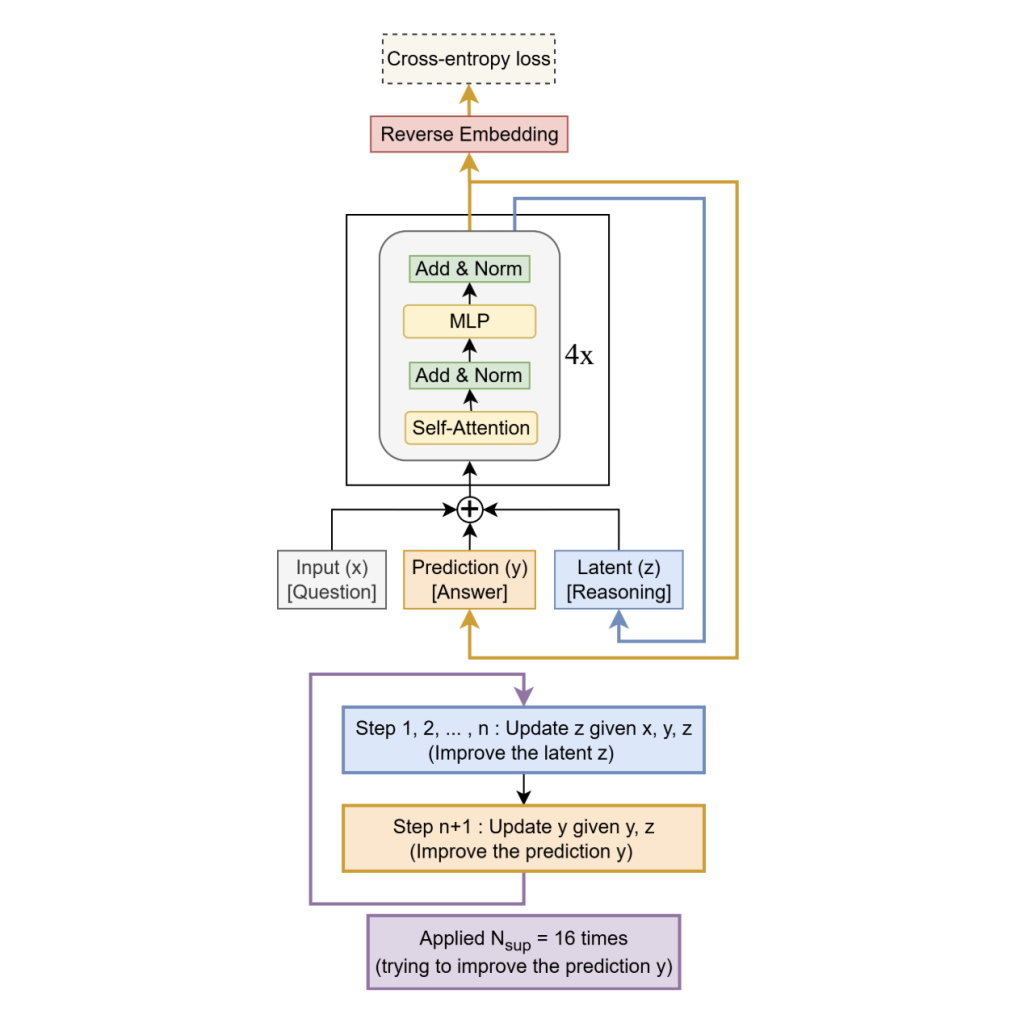
Architecturally, the best-performing setup for ARC/Maze retains self-attention; for Sudoku’s small fastened grids, the analysis crew swap self-attention for an MLP-Mixer-style token mixer. A small EMA (exponential shifting common) over weights stabilizes coaching on restricted information. Internet depth is successfully created by recursion (e.g., T = 3, n = 6) somewhat than stacking layers; in ablations, two layers generalize higher than deeper variants on the similar efficient compute.
Understanding the Outcomes
- ARC-AGI-1 / ARC-AGI-2 (two tries): TRM-Attn (7M): 44.6% / 7.8% vs HRM (27M): 40.3% / 5.0%. The analysis team-reported LLM baselines: DeepSeek-R1 (671B) 15.8% / 1.3%, o3-mini-high 34.5% / 3.0%, Gemini 2.5 Professional 37.0% / 4.9%; bigger bespoke Grok-4 entries are larger (66.7–79.6% / 16–29.4%).
- Sudoku-Excessive (9×9, 1K prepare / 423K check): 87.4% with attention-free mixer vs HRM 55.0%.
- Maze-Exhausting (30×30): 85.3% vs HRM 74.5%.
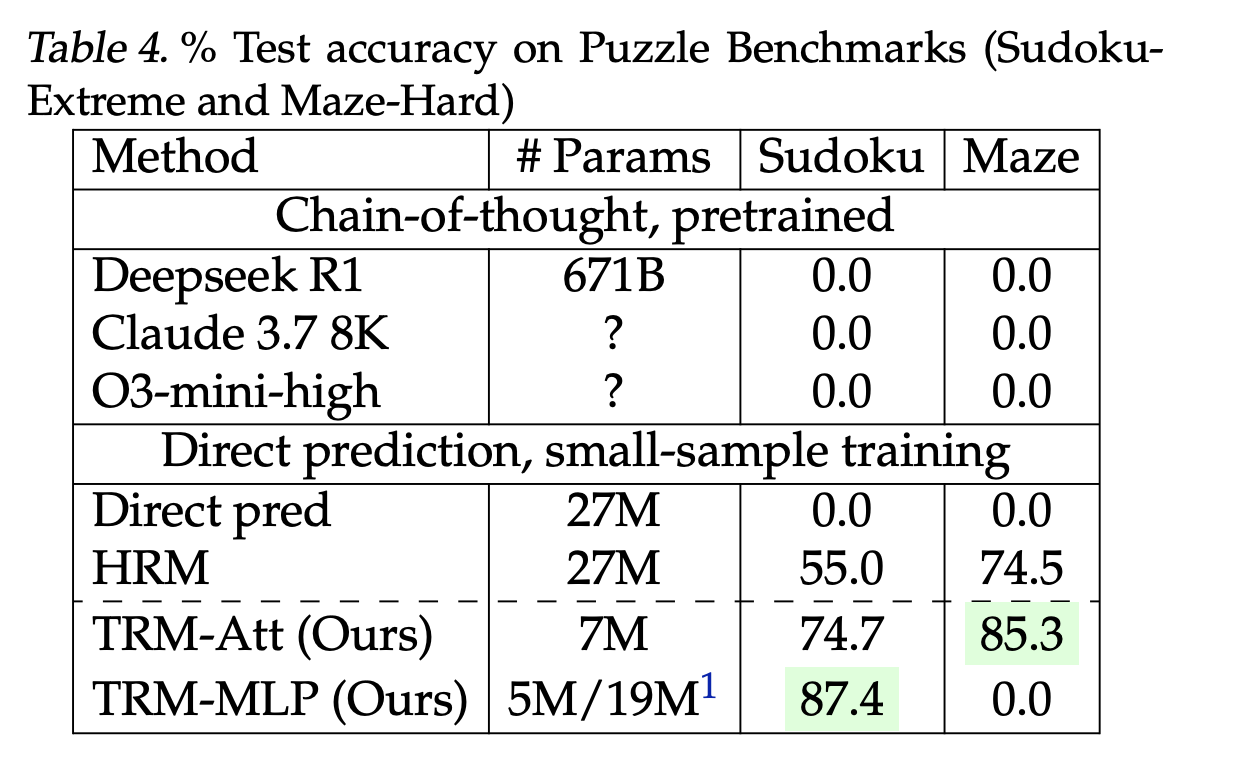
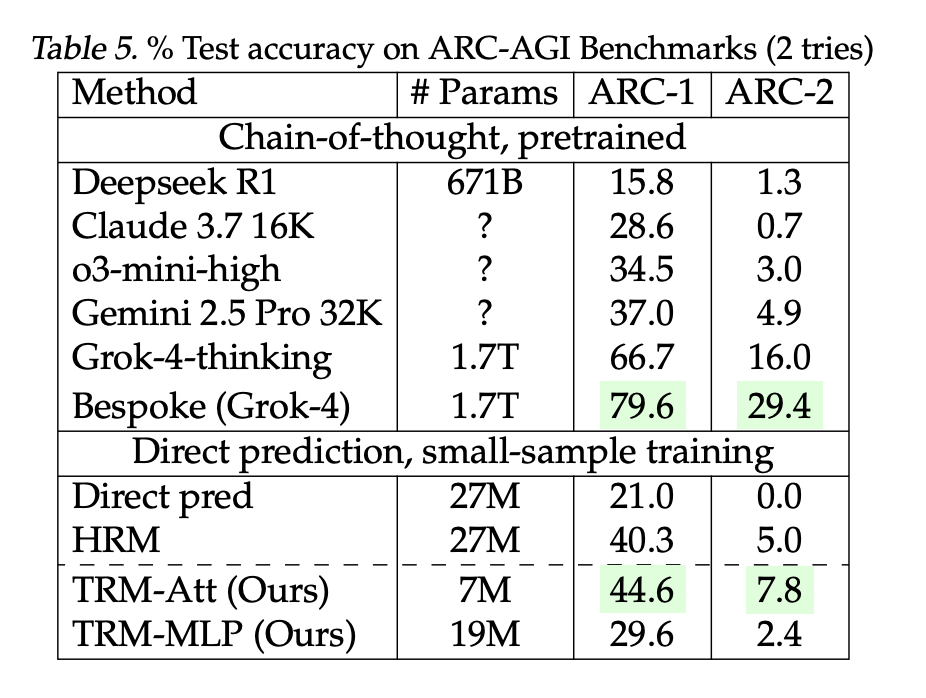
These are direct-prediction fashions educated from scratch on small, closely augmented datasets—not few-shot prompting. ARC stays the canonical goal; broader leaderboard context and guidelines (e.g., ARC-AGI-2 grand-prize threshold at 85% personal set) are tracked by the ARC Prize Basis.
Why a 7M mannequin can beat a lot bigger LLMs on these duties?
- Resolution-then-revision as a substitute of token-by-token: TRM drafts a full candidate answer, then improves it through latent iterative consistency checks towards the enter—decreasing publicity bias from autoregressive decoding on structured outputs.
- Compute spent on test-time reasoning, not parameter depend: Efficient depth arises from recursion (emulated depth ≈ T·(n+1)·layers), which the researchers present yields higher generalization at fixed compute than including layers.
- Tighter inductive bias to grid reasoning: For small fastened grids (e.g., Sudoku), attention-free mixing reduces overcapacity and improves bias/variance trade-offs; self-attention is stored for bigger 30×30 grids.
Key Takeaways
- Structure: A ~7M-param, 2-layer recursive solver that alternates latent “suppose” updates 𝑧 ← 𝑓 ( 𝑥 , 𝑦 , 𝑧 ) z←f(x,y,z) and an “act” refinement 𝑦 ← 𝑔 ( 𝑦 , 𝑧 ) y←g(y,z), unrolled as much as 16 steps with deep supervision; gradients are propagated by means of the complete recursion (no fixed-point/IFT approximation).
- Outcomes: Experiences ~44.6–45% on ARC-AGI-1 and ~7.8–8% on ARC-AGI-2 (two-try), surpassing a number of a lot bigger LLMs as cited within the analysis paper’s comparability (e.g., Gemini 2.5 Professional, o3-mini-high, DeepSeek-R1) below the said eval protocol.
- Effectivity/Sample: Demonstrates that allocating test-time compute to recursive refinement (depth through unrolling) can beat parameter scaling on symbolic-geometric duties, providing a compact, from-scratch recipe with publicly launched code.
This analysis demonstrates a ~7M-parameter, two-layer recursive solver that unrolls as much as 16 draft-revise cycles with ~6 latent updates per cycle and stories ~45% on ARC-AGI-1 and ~8% (two-try) on ARC-AGI-2. The analysis crew launched code on GitHub. ARC-AGI stays unsolved at scale (goal 85% on ARC-AGI-2), so the contribution is an architectural effectivity outcome somewhat than a normal reasoning breakthrough.
Try the Technical Paper and GitHub Web page. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.