

{kind=link}
Introduction
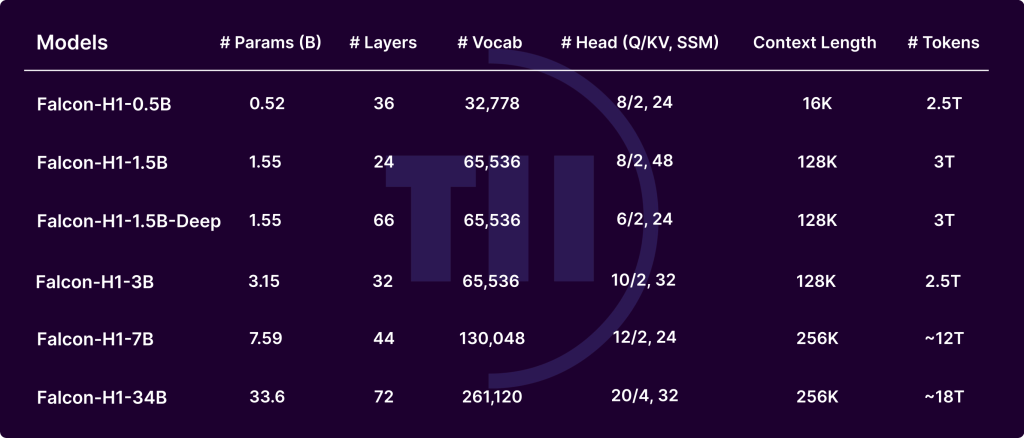
The Falcon-H1 collection, developed by the Expertise Innovation Institute (TII), marks a major development within the evolution of enormous language fashions (LLMs). By integrating Transformer-based consideration with Mamba-based State House Fashions (SSMs) in a hybrid parallel configuration, Falcon-H1 achieves distinctive efficiency, reminiscence effectivity, and scalability. Launched in a number of sizes (0.5B to 34B parameters) and variations (base, instruct-tuned, and quantized), Falcon-H1 fashions redefine the trade-off between compute finances and output high quality, providing parameter effectivity superior to many modern fashions reminiscent of Qwen2.5-72B and LLaMA3.3-70B.
Key Architectural Improvements
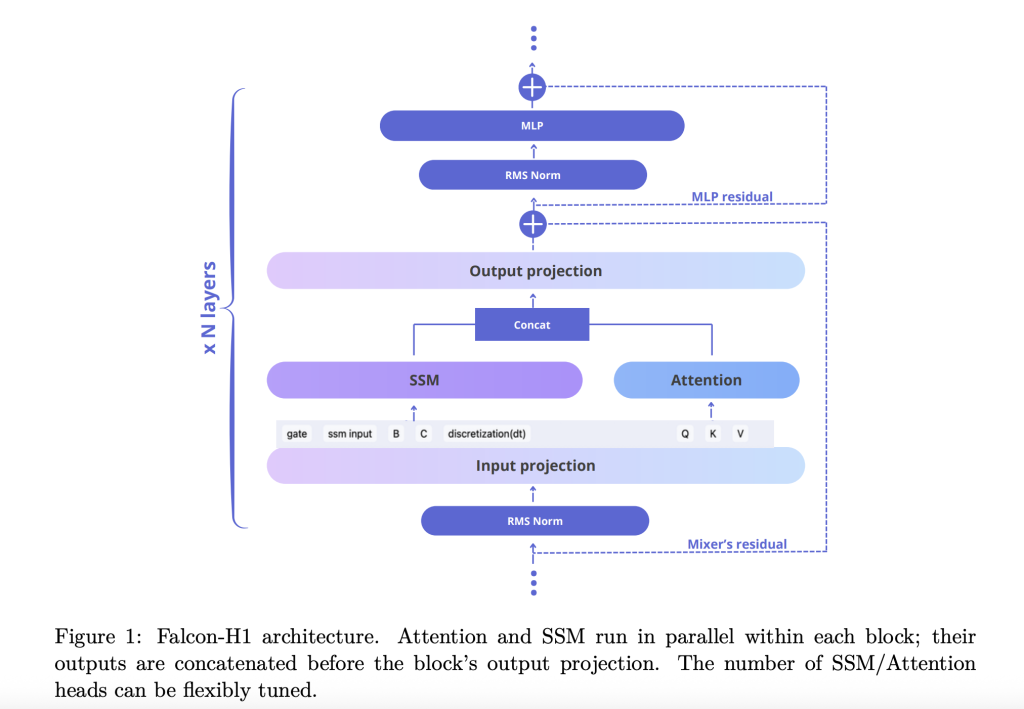
The technical report explains how Falcon-H1 adopts a novel parallel hybrid structure the place each consideration and SSM modules function concurrently, and their outputs are concatenated earlier than the projection. This design deviates from conventional sequential integration and gives the flexibleness to tune the variety of consideration and SSM channels independently. The default configuration makes use of a 2:1:5 ratio for SSM, consideration, and MLP channels respectively, optimizing each effectivity and studying dynamics.
To additional refine the mannequin, Falcon-H1 explores:
- Channel allocation: Ablations present that growing consideration channels deteriorates efficiency, whereas balancing SSM and MLP yields sturdy features.
- Block configuration: The SA_M configuration (semi-parallel with consideration and SSM run collectively, adopted by MLP) performs greatest in coaching loss and computational effectivity.
- RoPE base frequency: An unusually excessive base frequency of 10^11 in Rotary Positional Embeddings (RoPE) proved optimum, enhancing generalization throughout long-context coaching.
- Width-depth trade-off: Experiments present that deeper fashions outperform wider ones below mounted parameter budgets. Falcon-H1-1.5B-Deep (66 layers) outperforms many 3B and 7B fashions.
Tokenizer Technique
Falcon-H1 makes use of a custom-made Byte Pair Encoding (BPE) tokenizer suite with vocabulary sizes starting from 32K to 261K. Key design selections embody:
- Digit and punctuation splitting: Empirically improves efficiency in code and multilingual settings.
- LATEX token injection: Enhances mannequin accuracy on math benchmarks.
- Multilingual assist: Covers 18 languages and scales to 100+, utilizing optimized fertility and bytes/token metrics.
Pretraining Corpus and Knowledge Technique
Falcon-H1 fashions are skilled on as much as 18T tokens from a rigorously curated 20T token corpus, comprising:
- Excessive-quality internet information (filtered FineWeb)
- Multilingual datasets: Widespread Crawl, Wikipedia, arXiv, OpenSubtitles, and curated assets for 17 languages
- Code corpus: 67 languages, processed through MinHash deduplication, CodeBERT high quality filters, and PII scrubbing
- Math datasets: MATH, GSM8K, and in-house LaTeX-enhanced crawls
- Artificial information: Rewritten from uncooked corpora utilizing numerous LLMs, plus textbook-style QA from 30K Wikipedia-based matters
- Lengthy-context sequences: Enhanced through Fill-in-the-Center, reordering, and artificial reasoning duties as much as 256K tokens
Coaching Infrastructure and Methodology
Coaching utilized custom-made Maximal Replace Parametrization (µP), supporting clean scaling throughout mannequin sizes. The fashions make use of superior parallelism methods:
- Mixer Parallelism (MP) and Context Parallelism (CP): Improve throughput for long-context processing
- Quantization: Launched in bfloat16 and 4-bit variants to facilitate edge deployments
Analysis and Efficiency
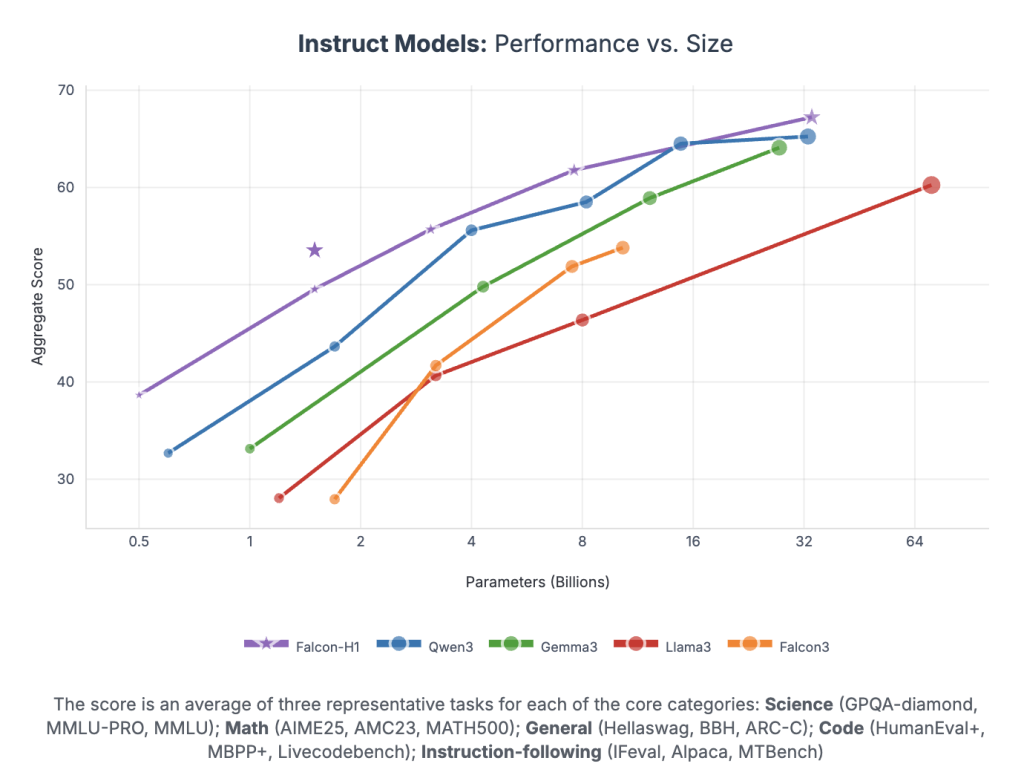
Falcon-H1 achieves unprecedented efficiency per parameter:
- Falcon-H1-34B-Instruct surpasses or matches 70B-scale fashions like Qwen2.5-72B and LLaMA3.3-70B throughout reasoning, math, instruction-following, and multilingual duties
- Falcon-H1-1.5B-Deep rivals 7B–10B fashions
- Falcon-H1-0.5B delivers 2024-era 7B efficiency
Benchmarks span MMLU, GSM8K, HumanEval, and long-context duties. The fashions display robust alignment through SFT and Direct Choice Optimization (DPO).
Conclusion
Falcon-H1 units a brand new customary for open-weight LLMs by integrating parallel hybrid architectures, versatile tokenization, environment friendly coaching dynamics, and sturdy multilingual functionality. Its strategic mixture of SSM and a spotlight permits for unmatched efficiency inside sensible compute and reminiscence budgets, making it supreme for each analysis and deployment throughout numerous environments.
Try the Paper and Fashions on Hugging Face. Be at liberty to examine our Tutorials web page on AI Agent and Agentic AI for numerous functions. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking complicated datasets into actionable insights.
