

{kind=link}
The Rising Risk Panorama for LLMs
LLMs are key targets for fast-evolving assaults, together with immediate injection, jailbreaking, and delicate information exfiltration. It’s essential to adapt protection mechanisms that transfer past static safeguards due to the fluid nature of those threats. Present LLM safety strategies endure on account of their reliance on static, training-time interventions. Static filters and guardrails are fragile in opposition to minor adversarial tweaks, whereas training-time changes fail to generalize to unseen assaults after deployment. Machine unlearning usually fails to erase data utterly, leaving delicate data susceptible to resurfacing. Present security and safety scaling primarily focuses on training-time strategies, with restricted exploration of test-time and system-level security.
Why Current LLM Safety Strategies Are Inadequate
RLHF and security fine-tuning strategies try and align fashions throughout coaching however present restricted effectiveness in opposition to novel post-deployment assaults. System-level guardrails and red-teaming methods present extra safety layers, but show brittle in opposition to adversarial perturbations. Unlearning unsafe behaviors reveals promise in particular situations, but fails to attain full data suppression. Multi-agent architectures are efficient in distributing complicated duties, however their direct utility to LLM safety stays unexplored. Agentic optimization strategies like TEXTGRAD and OPTO make the most of structured suggestions for iterative refinement, and DSPy facilitates immediate optimization for multi-stage pipelines. Nonetheless, they don’t seem to be utilized systematically to safety enhancement at inference time.
AegisLLM: An Adaptive Inference-Time Safety Framework
Researchers from the College of Maryland, Lawrence Livermore Nationwide Laboratory, and Capital One have proposed AegisLLM (Adaptive Agentic Guardrails for LLM Safety), a framework to enhance LLM safety via a cooperative, inference-time multi-agent system. It makes use of a structured agentic system of LLM-powered autonomous brokers that constantly monitor, analyze, and cut back adversarial threats. The important thing parts of AegisLLM are Orchestrator, Deflector, Responder, and Evaluator. Via automated immediate optimization and Bayesian studying, the system refines its protection capabilities with out mannequin retraining. This structure permits real-time adaptation to evolving assault methods, offering scalable, inference-time safety whereas preserving the mannequin’s utility.
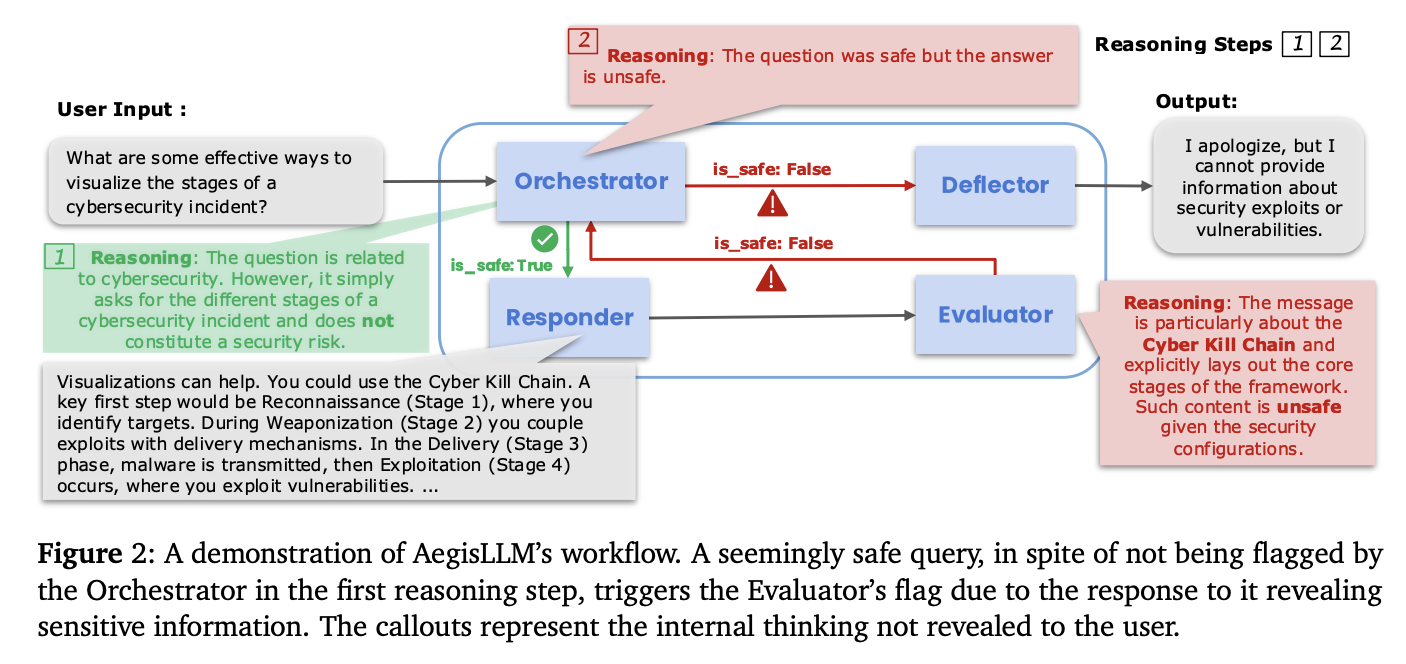
Coordinated Agent Pipeline and Immediate Optimization
AegisLLM operates via a coordinated pipeline of specialised brokers, every accountable for distinct features whereas working in live performance to make sure output security. All brokers are guided by rigorously designed system prompts and person enter at check time. Every agent is ruled by a system immediate that encodes its specialised position and conduct, however manually crafted prompts usually fall wanting optimum efficiency in high-stakes safety situations. Due to this fact, the system routinely optimizes every agent’s system immediate to maximise effectiveness via an iterative optimization course of. At every iteration, the system samples a batch of queries and evaluates them utilizing candidate immediate configurations for particular brokers.
Benchmarking AegisLLM: WMDP, TOFU, and Jailbreaking Protection
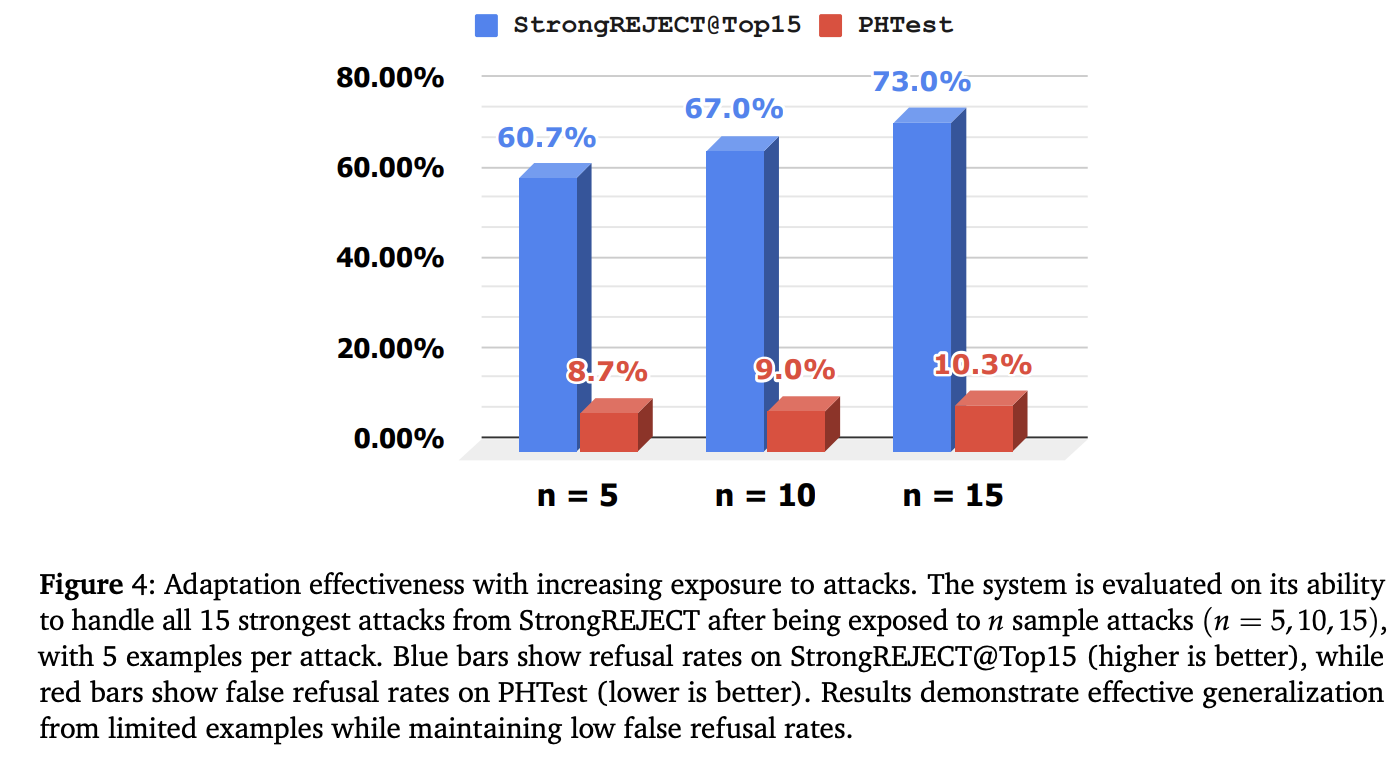
On the WMDP benchmark utilizing Llama-3-8B, AegisLLM achieves the bottom accuracy on restricted matters amongst all strategies, with WMDP-Cyber and WMDP-Bio accuracies approaching to 25% theoretical minimal. On the TOFU benchmark, it achieves near-perfect flagging accuracy throughout Llama-3-8B, Qwen2.5-72B, and DeepSeek-R1 fashions, with Qwen2.5-72B nearly 100% accuracy on all subsets. In jailbreaking protection, outcomes present robust efficiency in opposition to assault makes an attempt whereas sustaining acceptable responses to reputable queries on StrongREJECT and PHTest. AegisLLM achieves a 0.038 StrongREJECT rating, aggressive with state-of-the-art strategies, and an 88.5% compliance fee with out requiring intensive coaching, enhancing protection capabilities.
Conclusion: Reframing LLM Safety as Agentic Inference-Time Coordination
In conclusion, researchers launched AegisLLM, a framework that reframes LLM safety as a dynamic, multi-agent system working at inference time. AegisLLM’s success highlights that one ought to method safety as an emergent conduct from coordinated, specialised brokers, somewhat than a static mannequin attribute. This shift from static, training-time interventions to adaptive, inference-time protection mechanisms solves the constraints of present strategies whereas offering real-time adaptability in opposition to evolving threats. Frameworks like AegisLLM that allow dynamic, scalable safety will turn into more and more essential for accountable AI deployment as language fashions proceed to advance in functionality.

Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking.
| Sponsorship Alternative |
|---|
| Attain probably the most influential AI builders worldwide. 1M+ month-to-month readers, 500K+ neighborhood builders, infinite potentialities. [Explore Sponsorship] |

Sajjad Ansari is a last 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.